Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Sintesi del comunicato stampa
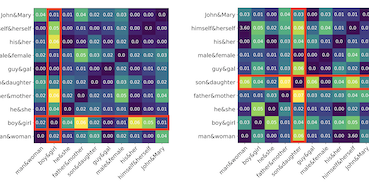
I ricercatori della University of Virginia e di Salesforce Research hanno individuato un fattore precedentemente trascurato che compromette le tecniche comuni per rimuovere il pregiudizio di genere dai word embedding — la frequenza statistica delle parole nei dati di addestramento. I word embedding, le rappresentazioni numeriche del linguaggio utilizzate in innumerevoli applicazioni di IA e di elaborazione del linguaggio naturale, sono noti per codificare stereotipi di genere della società, come l'associazione di "programmer" agli uomini e di "homemaker" alle donne. La soluzione dominante a questo problema, un algoritmo chiamato Hard Debias, funziona individuando e proiettando fuori una "direzione di genere" dallo spazio degli embedding, ma i ricercatori hanno scoperto che le informazioni sulla frequenza delle parole incorporate negli embedding distorcono quella direzione di genere prima che possa essere rimossa in modo pulito. Per affrontare questo problema, hanno costruito un metodo in due fasi chiamato Double-Hard Debias, che prima elimina la componente legata alla frequenza degli embedding e poi applica la procedura standard di Hard Debias. Testando gli embedding GloVe e Word2Vec su tre benchmark standard di pregiudizio — tra cui un compito di risoluzione delle coreferenze, un test di associazione di parole e un controllo geometrico basato sul clustering — il loro approccio ha ridotto il pregiudizio di genere misurabile in misura più sostanziale rispetto ai metodi precedenti, con il divario tra le prestazioni di un sistema di coreferenza su frasi stereotipate per genere rispetto a frasi contro-stereotipate che è sceso da 15,2 punti percentuali con GloVe non modificato ad appena 0,9 con il loro metodo, mentre la qualità linguistica generale sui compiti di analogia e categorizzazione di parole è rimasta in gran parte intatta. Il lavoro suggerisce che ripulire i word embedding richiede di prestare maggiore attenzione agli artefatti strutturali lasciati dalle statistiche del corpus.
abstract
I word embedding derivati da corpora generati da esseri umani ereditano un forte pregiudizio di genere che può essere ulteriormente amplificato dai modelli a valle. Alcuni approcci di debiasing comunemente adottati, incluso il fondamentale algoritmo Hard Debias, applicano procedure di post-elaborazione che proiettano i word embedding preaddestrati in un sottospazio ortogonale a un sottospazio di genere inferito. Scopriamo che regolarità del corpus indipendenti dalla semantica, come la frequenza delle parole catturata dai word embedding, influiscono negativamente sulle prestazioni di questi algoritmi. Proponiamo una tecnica semplice ma efficace, Double Hard Debias, che purifica i word embedding da tali regolarità del corpus prima di inferire e rimuovere il sottospazio di genere. Esperimenti su tre benchmark di mitigazione del pregiudizio mostrano che il nostro approccio preserva la semantica distribuzionale dei word embedding preaddestrati riducendo al contempo il pregiudizio di genere in misura significativamente maggiore rispetto agli approcci precedenti.
dettagli
citazione
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}