Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Resumo do comunicado de imprensa
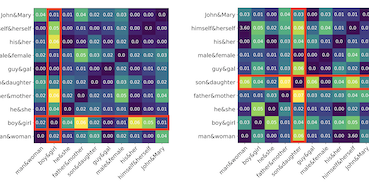
Pesquisadores da University of Virginia e da Salesforce Research identificaram um fator anteriormente negligenciado que prejudica técnicas comuns de remoção de viés de gênero de embeddings de palavras — a frequência estatística das palavras nos dados de treinamento. Os embeddings de palavras, as representações numéricas da linguagem usadas em inúmeras aplicações de IA e de processamento de linguagem natural, são conhecidos por codificar estereótipos sociais de gênero, como associar "programmer" a homens e "homemaker" a mulheres. A correção dominante para esse problema, um algoritmo chamado Hard Debias, funciona identificando e projetando para fora uma "direção de gênero" do espaço de embeddings, mas os pesquisadores descobriram que a informação de frequência de palavras embutida nos embeddings distorce essa direção de gênero antes que ela possa ser removida de forma limpa. Para resolver isso, eles construíram um método de duas etapas chamado Double-Hard Debias, que primeiro retira o componente relacionado à frequência dos embeddings e depois aplica o procedimento padrão Hard Debias. Testando em embeddings GloVe e Word2Vec em três benchmarks padrão de viés — incluindo uma tarefa de resolução de correferência, um teste de associação de palavras e uma verificação geométrica baseada em agrupamento — sua abordagem reduziu o viés de gênero mensurável de forma mais substancial do que os métodos anteriores, com a diferença entre o desempenho de um sistema de correferência em frases estereotípicas de gênero versus contraestereotípicas caindo de 15,2 pontos percentuais com o GloVe não modificado para apenas 0,9 com seu método, enquanto a qualidade geral da linguagem em tarefas de analogia e categorização de palavras permaneceu em grande parte intacta. O trabalho sugere que limpar embeddings de palavras requer prestar mais atenção aos artefatos estruturais que as estatísticas do corpus deixam para trás.
resumo
Embeddings de palavras derivados de corpora gerados por humanos herdam um forte viés de gênero que pode ser ainda mais amplificado por modelos posteriores. Algumas abordagens de remoção de viés comumente adotadas, incluindo o seminal algoritmo Hard Debias, aplicam procedimentos de pós-processamento que projetam embeddings de palavras pré-treinados em um subespaço ortogonal a um subespaço de gênero inferido. Descobrimos que regularidades do corpus agnósticas à semântica, como a frequência de palavras capturada pelos embeddings, impactam negativamente o desempenho desses algoritmos. Propomos uma técnica simples, mas eficaz, o Double Hard Debias, que purifica os embeddings de palavras contra tais regularidades do corpus antes de inferir e remover o subespaço de gênero. Experimentos em três benchmarks de mitigação de viés mostram que nossa abordagem preserva a semântica distribucional dos embeddings de palavras pré-treinados, ao mesmo tempo em que reduz o viés de gênero em grau significativamente maior do que as abordagens anteriores.
detalhes
citação
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}