FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Zusammenfassung der Pressemitteilung
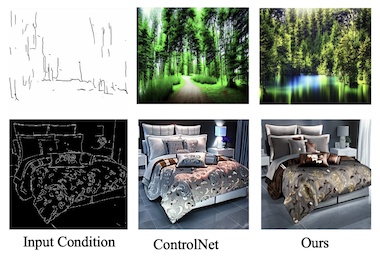
Forschende der UC Santa Cruz, von Amazon, der UNC Chapel Hill, der Rice University und der UCLA haben eine effizientere Methode entwickelt, KI-Bildgeneratoren mit mehreren Arten visueller Anleitung gleichzeitig zu steuern. Aktuelle Text-zu-Bild-Diffusionsmodelle wie Stable Diffusion lassen sich durch strukturelle Eingaben wie Kantenkarten, Tiefenkarten und Segmentierungskarten lenken, aber das Training dieser steuerbaren Systeme erfordert typischerweise erhebliche Rechenressourcen, die linear ansteigen, je mehr Eingabetypen hinzugefügt werden. Das neue System des Teams, genannt FlexEControl, geht dies an, indem es eine mathematische Technik namens Kronecker-Zerlegung aus der breiteren Literatur des maschinellen Lernens übernimmt und damit eine kompakte Menge gemeinsamer Gewichte erzeugt, die verschiedene Eingabemodalitäten bewältigt, statt für jede separate Parameter zu lernen. Das Ergebnis ist ein Modell, das 41 % weniger trainierbare Parameter und 30 % weniger Speicher als ein führendes vergleichbares System namens UniControlNet verwendet, während es die Trainingszeit pro Iteration von etwa 5,7 Sekunden auf 2,1 Sekunden senkt. Über die reine Effizienz hinaus schneidet FlexEControl auch besser ab, wenn es mehrere widersprüchliche oder redundante Eingaben jongliert — etwa zwei verschiedene Kantenkarten derselben Szene — ein Szenario, in dem bestehende Methoden dazu neigen, verworrene oder inkohärente Bilder zu erzeugen. Die Forschenden erreichten dies, indem sie zwei spezialisierte Trainings-Verlustfunktionen hinzufügten, die das Modell zwingen, auf die richtigen räumlichen Regionen zu achten und seine Ausgaben an den entsprechenden Text-Prompts auszurichten. In menschlichen Bewertungen bevorzugten Annotatoren in 64 % der Fälle die Ausgaben von FlexEControl gegenüber denen von UniControlNet, wenn beide Systeme mehrere Eingaben desselben Typs erhielten. Die Arbeit ist von Bedeutung, weil die Verbilligung steuerbarer Bildgenerierung und ihre verbesserte Fähigkeit, komplexe, gemischte Eingaben zu bewältigen, den Zugang zu diesen Werkzeugen für Entwickler und Forschende mit begrenzten Rechenressourcen spürbar erweitern könnte.
Zusammenfassung
Steuerbare Text-zu-Bild- (T2I) Diffusionsmodelle generieren Bilder, die sowohl auf Text-Prompts als auch auf semantische Eingaben anderer Modalitäten wie Kantenkarten konditioniert sind. Dennoch stehen aktuelle steuerbare T2I-Methoden häufig vor Herausforderungen in Bezug auf Effizienz und Treue, insbesondere bei der Konditionierung auf mehrere Eingaben aus derselben oder aus verschiedenen Modalitäten. In dieser Arbeit schlagen wir eine neuartige flexible und effiziente Methode, FlexEControl, für die steuerbare T2I-Generierung vor. Den Kern von FlexEControl bildet eine einzigartige Strategie zur Gewichtszerlegung, die eine reibungslose Integration verschiedener Eingabetypen ermöglicht. Dieser Ansatz erhöht nicht nur die Treue des generierten Bildes zur Steuerung, sondern reduziert auch den Rechenaufwand erheblich, der typischerweise mit multimodaler Konditionierung verbunden ist. Unser Ansatz erreicht eine Reduzierung der trainierbaren Parameter um 41 % und der Speichernutzung um 30 % im Vergleich zu Uni-ControlNet. Darüber hinaus verdoppelt er die Dateneffizienz und kann Bilder flexibel unter der Anleitung mehrerer Eingabebedingungen verschiedener Modalitäten generieren.
Zitation
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}