Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Zusammenfassung der Pressemitteilung
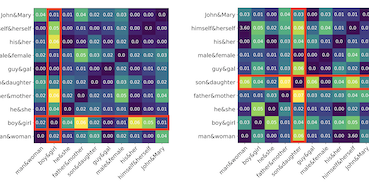
Forscher der University of Virginia und von Salesforce Research haben einen zuvor übersehenen Faktor identifiziert, der gängige Techniken zur Beseitigung von Geschlechterbias aus Word Embeddings untergräbt — die statistische Häufigkeit von Wörtern in den Trainingsdaten. Word Embeddings, die numerischen Repräsentationen von Sprache, die in unzähligen KI- und Anwendungen zur Verarbeitung natürlicher Sprache verwendet werden, kodieren bekanntermaßen gesellschaftliche Geschlechterstereotype, etwa indem sie "programmer" mit Männern und "homemaker" mit Frauen assoziieren. Die vorherrschende Lösung für dieses Problem, ein Algorithmus namens Hard Debias, funktioniert, indem er eine "Geschlechterrichtung" im Embedding-Raum identifiziert und herausprojiziert, doch die Forscher stellten fest, dass in die Embeddings eingebrannte Worthäufigkeitsinformationen diese Geschlechterrichtung verzerren, bevor sie sauber entfernt werden kann. Um dem zu begegnen, entwickelten sie eine zweistufige Methode namens Double-Hard Debias, die zunächst die häufigkeitsbezogene Komponente der Embeddings herauslöst und dann das standardmäßige Hard-Debias-Verfahren anwendet. Beim Testen an GloVe- und Word2Vec-Embeddings über drei Standard-Bias-Benchmarks hinweg — darunter eine Aufgabe zur Koreferenzauflösung, ein Worteassoziationstest und eine clusterbasierte Geometrieprüfung — reduzierte ihr Ansatz den messbaren Geschlechterbias deutlich stärker als frühere Methoden, wobei die Lücke zwischen der Leistung eines Koreferenzsystems bei geschlechtsstereotypen gegenüber gegenstereotypen Sätzen von 15,2 Prozentpunkten beim unveränderten GloVe auf nur 0,9 mit ihrer Methode sank, während die allgemeine Sprachqualität bei Wortanalogie- und Kategorisierungsaufgaben weitgehend erhalten blieb. Die Arbeit legt nahe, dass das Bereinigen von Word Embeddings eine genauere Beachtung der strukturellen Artefakte erfordert, die Korpusstatistiken hinterlassen.
Zusammenfassung
Word Embeddings, die aus von Menschen erzeugten Korpora abgeleitet werden, erben einen starken Geschlechterbias, der durch nachgelagerte Modelle weiter verstärkt werden kann. Einige gängig eingesetzte Debiasing-Ansätze, darunter der wegweisende Hard-Debias-Algorithmus, wenden Nachbearbeitungsverfahren an, die vortrainierte Word Embeddings in einen Unterraum projizieren, der orthogonal zu einem abgeleiteten Geschlechter-Unterraum ist. Wir entdecken, dass semantik-agnostische Korpus-Regelmäßigkeiten wie die von den Word Embeddings erfasste Worthäufigkeit die Leistung dieser Algorithmen negativ beeinflussen. Wir schlagen eine einfache, aber wirksame Technik vor, Double Hard Debias, die die Word Embeddings von solchen Korpus-Regelmäßigkeiten bereinigt, bevor der Geschlechter-Unterraum abgeleitet und entfernt wird. Experimente auf drei Benchmarks zur Bias-Minderung zeigen, dass unser Ansatz die distributionelle Semantik der vortrainierten Word Embeddings bewahrt und dabei den Geschlechterbias in deutlich größerem Maße reduziert als frühere Ansätze.
Details
Zitation
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}