Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Resumen de prensa
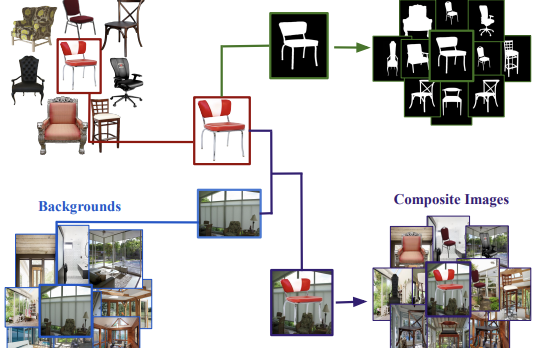
Investigadores de la Universidad de Virginia e instituciones colaboradoras han publicado un nuevo conjunto de datos llamado Chair Segments, diseñado para ofrecer a los científicos de visión por computador una forma más rápida y económica de probar algoritmos de segmentación de imágenes. El problema central que identificaron es que los conjuntos de datos de segmentación existentes —como COCO o PASCAL VOC— son grandes, costosos de anotar y obligan a los modelos a manejar simultáneamente el reconocimiento de objetos, la localización y el enmascaramiento a nivel de píxel, lo que dificulta aislar e iterar rápidamente sobre ideas específicas de segmentación. Para sortear esto, el equipo construyó un conjunto de datos semisintético de aproximadamente 900 imágenes de sillas con fondos transparentes, compuestas sobre 10.000 imágenes de escenas diversas, interiores y exteriores, produciendo 50.000 composiciones de entrenamiento con máscaras de verdad fundamental perfectas a nivel de píxel que no requirieron ninguna anotación manual. Los investigadores eligieron las sillas deliberadamente: la categoría es notoriamente difícil de segmentar debido a sus partes delgadas, huecas y autoocluyentes, y se sitúa entre las más difíciles de los benchmarks existentes. Sus experimentos mostraron que un modelo U-Net puede entrenarse hasta su convergencia total en el conjunto de datos en unos 30 minutos en una única GPU a una resolución de 64×64 —aproximadamente el nivel de complejidad de CIFAR-10 para la clasificación— sin dejar de distinguir significativamente entre arquitecturas más fuertes y más débiles. Es importante destacar que los modelos preentrenados en Chair Segments y luego ajustados finamente en el conjunto de datos no relacionado Object Discovery (que abarca coches, caballos y aviones) superaron a todos los métodos publicados anteriormente en ese benchmark, lo que sugiere que los datos semisintéticos capturan características del mundo real genuinamente útiles. El equipo también confirmó, por primera vez en segmentación, un patrón previamente observado en la clasificación de imágenes: los modelos ajustados finamente a partir de los mismos pesos preentrenados se agrupan en el paisaje de optimización y transitan suavemente de uno a otro, mientras que los modelos entrenados a partir de una inicialización aleatoria no lo hacen, un hallazgo con implicaciones prácticas para cómo podrían inicializarse y ensamblarse los modelos de segmentación.
resumen
A lo largo de los años, los conjuntos de datos y los benchmarks han tenido una influencia desmesurada en el diseño de algoritmos novedosos. En este artículo, presentamos ChairSegments, un conjunto de datos semisintético, novedoso y compacto para la segmentación de objetos. También mostramos hallazgos empíricos en aprendizaje por transferencia que reflejan hallazgos recientes para la clasificación de imágenes. En particular, mostramos que los modelos que se ajustan finamente a partir de un conjunto preentrenado de pesos se sitúan en la misma cuenca del paisaje de optimización. ChairSegments consiste en un conjunto diverso de imágenes prototípicas de sillas con fondos transparentes compuestas sobre una variada gama de fondos. Aspiramos a que ChairSegments sea el equivalente del conjunto de datos CIFAR-10 pero para diseñar e iterar rápidamente sobre arquitecturas de modelo novedosas para la segmentación. En Chair Segments, un modelo U-Net puede entrenarse hasta su convergencia total en solo treinta minutos usando una única GPU. Por último, si bien este conjunto de datos es semisintético, puede ser un sustituto útil de datos reales, conduciendo a una precisión de vanguardia en el conjunto de datos Object Discovery cuando se usa como fuente de preentrenamiento.
detalles
cita
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}