Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Résumé du communiqué de presse
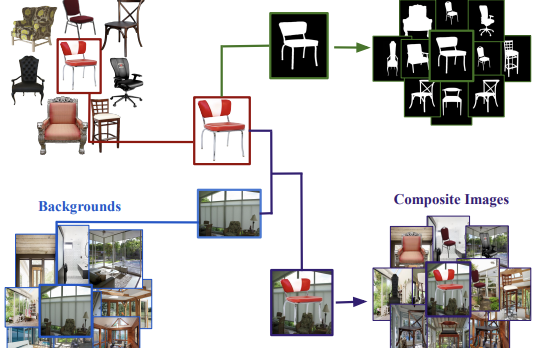
Des chercheurs de l'université de Virginie et d'établissements partenaires ont publié un nouveau jeu de données appelé Chair Segments, conçu pour offrir aux scientifiques de la vision par ordinateur un moyen plus rapide et moins coûteux de tester des algorithmes de segmentation d'images. Le problème central qu'ils ont identifié est que les jeux de données de segmentation existants — comme COCO ou PASCAL VOC — sont volumineux, coûteux à annoter et obligent les modèles à gérer simultanément la reconnaissance d'objets, la localisation et le masquage au niveau du pixel, ce qui rend difficile l'isolement et l'itération rapide d'idées propres à la segmentation. Pour contourner cela, l'équipe a construit un jeu de données semi-synthétique d'environ 900 images de chaises à fond transparent, composées sur 10 000 images de scènes intérieures et extérieures variées, produisant 50 000 composites d'entraînement avec des masques de vérité terrain parfaits au pixel près, ne nécessitant aucune annotation manuelle. Les chercheurs ont choisi les chaises délibérément : cette catégorie est notoirement difficile à segmenter en raison de ses parties fines, creuses et auto-occlusives, et elle figure parmi les plus ardues des benchmarks existants. Leurs expériences ont montré qu'un modèle U-Net peut être entraîné jusqu'à pleine convergence sur ce jeu de données en environ 30 minutes sur un seul GPU à une résolution de 64×64 — soit à peu près le niveau de complexité de CIFAR-10 pour la classification — tout en distinguant encore de manière significative les architectures plus ou moins performantes. Fait important, les modèles pré-entraînés sur Chair Segments puis affinés sur le jeu de données sans rapport Object Discovery (couvrant voitures, chevaux et avions) ont surpassé toutes les méthodes publiées jusque-là sur ce benchmark, ce qui suggère que les données semi-synthétiques capturent des caractéristiques réellement utiles du monde réel. L'équipe a également confirmé, pour la première fois en segmentation, un schéma précédemment observé en classification d'images : les modèles affinés à partir des mêmes poids pré-entraînés se regroupent dans le paysage d'optimisation et passent en douceur de l'un à l'autre, tandis que les modèles entraînés à partir d'une initialisation aléatoire ne le font pas — un constat aux implications pratiques pour la façon dont les modèles de segmentation pourraient être initialisés et assemblés.
résumé
Au fil des ans, les jeux de données et les benchmarks ont exercé une influence démesurée sur la conception d'algorithmes nouveaux. Dans cet article, nous présentons ChairSegments, un jeu de données semi-synthétique nouveau et compact dédié à la segmentation d'objets. Nous présentons également des résultats empiriques en apprentissage par transfert qui reflètent des constatations récentes en classification d'images. Nous montrons en particulier que les modèles affinés à partir d'un ensemble de poids pré-entraînés se situent dans le même bassin du paysage d'optimisation. ChairSegments est constitué d'un ensemble varié d'images prototypiques de chaises à fond transparent composées sur une grande diversité d'arrière-plans. Nous souhaitons que ChairSegments soit l'équivalent du jeu de données CIFAR-10, mais destiné à concevoir et à itérer rapidement sur de nouvelles architectures de modèles pour la segmentation. Sur Chair Segments, un modèle U-Net peut être entraîné jusqu'à pleine convergence en seulement trente minutes à l'aide d'un seul GPU. Enfin, bien que ce jeu de données soit semi-synthétique, il peut constituer un substitut utile aux données réelles, conduisant à une précision à l'état de l'art sur le jeu de données Object Discovery lorsqu'il est utilisé comme source de pré-entraînement.
détails
citation
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}