Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Sintesi del comunicato stampa
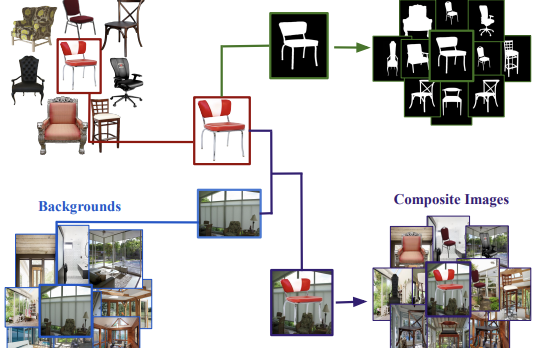
I ricercatori della University of Virginia e istituzioni collaboratrici hanno rilasciato un nuovo dataset chiamato Chair Segments, progettato per offrire agli scienziati della visione artificiale un modo più rapido ed economico per testare gli algoritmi di segmentazione di immagini. Il problema centrale che hanno individuato è che i dataset di segmentazione esistenti — come COCO o PASCAL VOC — sono grandi, costosi da annotare e costringono i modelli a gestire contemporaneamente il riconoscimento, la localizzazione e il mascheramento a livello di pixel degli oggetti, rendendo difficile isolare e iterare rapidamente su idee specifiche per la segmentazione. Per aggirare questo problema, il team ha costruito un dataset semi-sintetico di circa 900 immagini di sedie con sfondi trasparenti, composite su 10.000 immagini diversificate di scene interne ed esterne, producendo 50.000 composizioni di addestramento con maschere di verità fondamentale perfette a livello di pixel che non hanno richiesto alcuna annotazione manuale. I ricercatori hanno scelto le sedie deliberatamente: la categoria è notoriamente difficile da segmentare a causa di parti sottili, cave e che si auto-occludono, ed è tra le più ardue nei benchmark esistenti. I loro esperimenti hanno mostrato che un modello U-Net può essere addestrato fino alla piena convergenza sul dataset in circa 30 minuti su una singola GPU a risoluzione 64×64 — all'incirca il livello di complessità di CIFAR-10 per la classificazione — pur distinguendo in modo significativo tra architetture più forti e più deboli. È importante notare che i modelli preaddestrati su Chair Segments e poi perfezionati sul dataset Object Discovery non correlato (che copre automobili, cavalli e aeroplani) hanno battuto tutti i metodi pubblicati in precedenza su quel benchmark, suggerendo che i dati semi-sintetici catturano caratteristiche del mondo reale realmente utili. Il team ha inoltre confermato, per la prima volta nella segmentazione, uno schema osservato in precedenza nella classificazione di immagini: i modelli perfezionati dagli stessi pesi preaddestrati si raggruppano nel paesaggio di ottimizzazione e transitano agevolmente l'uno nell'altro, mentre i modelli addestrati da inizializzazione casuale non lo fanno — una scoperta con implicazioni pratiche su come i modelli di segmentazione potrebbero essere inizializzati e combinati in ensemble.
abstract
Nel corso degli anni, i dataset e i benchmark hanno avuto un'influenza enorme sulla progettazione di nuovi algoritmi. In questo articolo presentiamo ChairSegments, un nuovo dataset semi-sintetico e compatto per la segmentazione di oggetti. Mostriamo inoltre risultati empirici nel transfer learning che rispecchiano le recenti scoperte relative alla classificazione di immagini. In particolare, mostriamo che i modelli perfezionati a partire da un insieme di pesi preaddestrati si collocano nello stesso bacino del paesaggio di ottimizzazione. ChairSegments è costituito da un insieme diversificato di immagini prototipiche di sedie con sfondi trasparenti composite su una vasta gamma di sfondi. Il nostro obiettivo è che ChairSegments sia l'equivalente del dataset CIFAR-10 ma per progettare e iterare rapidamente su nuove architetture di modelli per la segmentazione. Su Chair Segments, un modello U-Net può essere addestrato fino alla piena convergenza in soli trenta minuti utilizzando una singola GPU. Infine, sebbene questo dataset sia semi-sintetico, può costituire un utile surrogato dei dati reali, portando a un'accuratezza allo stato dell'arte sul dataset Object Discovery quando utilizzato come fonte di preaddestramento.
dettagli
citazione
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}