プレスリリース要約
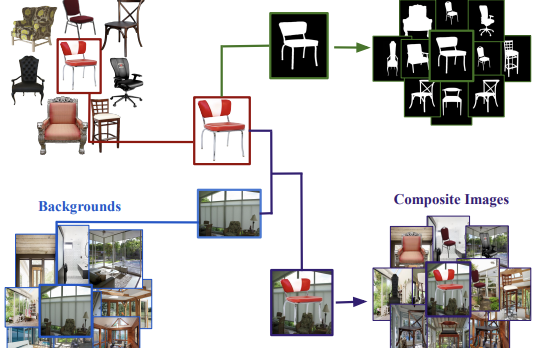
バージニア大学および協力機関の研究者らは、コンピュータビジョンの科学者が画像セグメンテーションアルゴリズムをより速く、より安価にテストできるようにすることを目的とした、Chair Segmentsと呼ばれる新しいデータセットを公開した。彼らが特定した中心的な問題は、COCOやPASCAL VOCのような既存のセグメンテーションデータセットが大規模でアノテーションに費用がかかり、モデルに物体認識、位置特定、画素単位のマスキングを同時に処理させることを強いるため、セグメンテーション特有のアイデアを切り出して迅速に反復することが難しいという点である。これを回避するために、チームは透明な背景を持つ約900枚の椅子画像を10,000枚の多様な屋内外シーン画像に合成し、手作業のアノテーションを一切必要としない画素単位で正確な正解マスク付きの50,000枚の訓練用合成画像からなる半合成データセットを構築した。研究者らが意図的に椅子を選んだ理由は、このカテゴリが細く、中空で、自己遮蔽する部分のためにセグメンテーションが非常に難しいことで知られ、既存のベンチマークの中でも最も困難なものの一つに位置づけられるからである。彼らの実験では、U-Netモデルを64×64の解像度で単一のGPUを用いて約30分でこのデータセット上で完全な収束まで訓練でき、これは分類におけるCIFAR-10とほぼ同程度の複雑さでありながら、強いアーキテクチャと弱いアーキテクチャを依然として意味のある形で区別できることが示された。重要なことに、Chair Segmentsで事前学習し、その後無関係なObject Discoveryデータセット(自動車、馬、飛行機を対象とする)でファインチューニングしたモデルは、そのベンチマークでこれまで発表されたすべての手法を上回り、半合成データが現実世界の真に有用な特徴を捉えていることを示唆している。チームはまた、これまで画像分類で観察されていたパターンをセグメンテーションにおいて初めて確認した。すなわち、同じ事前学習済みの重みからファインチューニングされたモデルは最適化ランドスケープにおいて互いに集まり、滑らかに移行し合うのに対し、ランダムな初期化から訓練されたモデルはそうならないという知見であり、これはセグメンテーションモデルをどのように初期化し、アンサンブルすべきかについて実用的な示唆を持つ。
要旨
長年にわたり、データセットとベンチマークは新規アルゴリズムの設計に多大な影響を及ぼしてきた。本論文では、物体セグメンテーションのための新規かつコンパクトな半合成データセットであるChairSegmentsを紹介する。また、画像分類に関する最近の知見を反映する転移学習の実証的知見も示す。特に、事前学習済みの重みの集合からファインチューニングされたモデルが、最適化ランドスケープの同じ盆地に位置することを示す。ChairSegmentsは、透明な背景を持つ椅子の典型的な画像の多様な集合を、多様な背景に合成したものから構成される。我々は、ChairSegmentsをCIFAR-10データセットに相当するものとしつつ、セグメンテーションのための新規なモデルアーキテクチャを迅速に設計し反復するためのものとすることを目指している。Chair Segmentsでは、U-Netモデルを単一のGPUを用いてわずか30分で完全な収束まで訓練できる。最後に、このデータセットは半合成であるものの、実データの有用な代替となりうるものであり、事前学習の元として用いた場合にObject Discoveryデータセットで最先端の精度をもたらす。
詳細
引用
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}