このデモは、任意の入力テキストに条件づけて画像内の領域を強調しようとするものです。
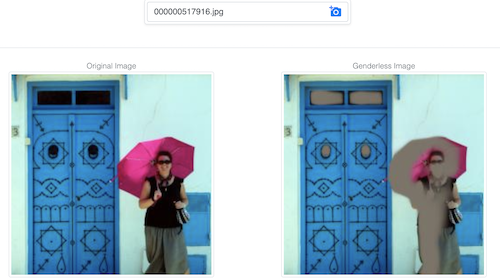
このデモは、画像の情報の大部分を保持したまま、モデルが画像から性別を予測することを困難にするように画像を変更しようとするものです。
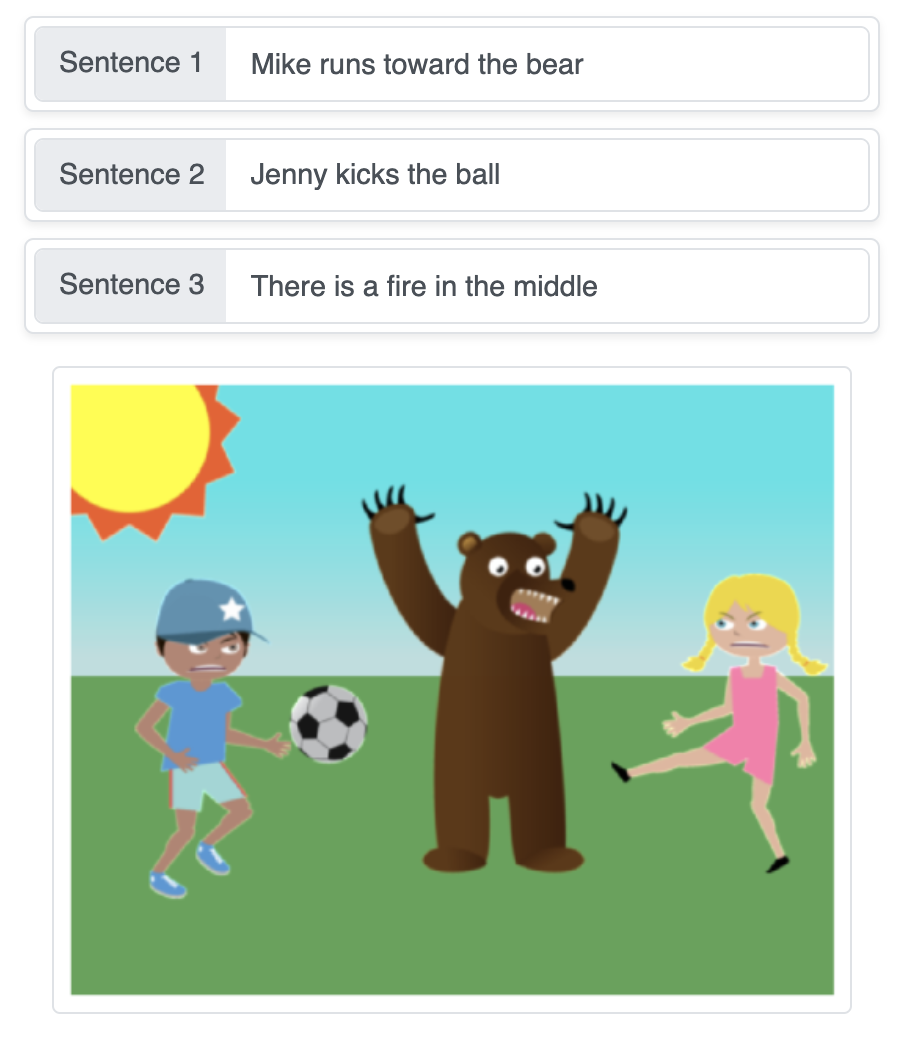
このデモは、シーケンス生成ニューラルネットワークを用いて、無地の背景にオブジェクトを順番に配置することで、テキストによる記述を自動生成されたシーンへと変換します。
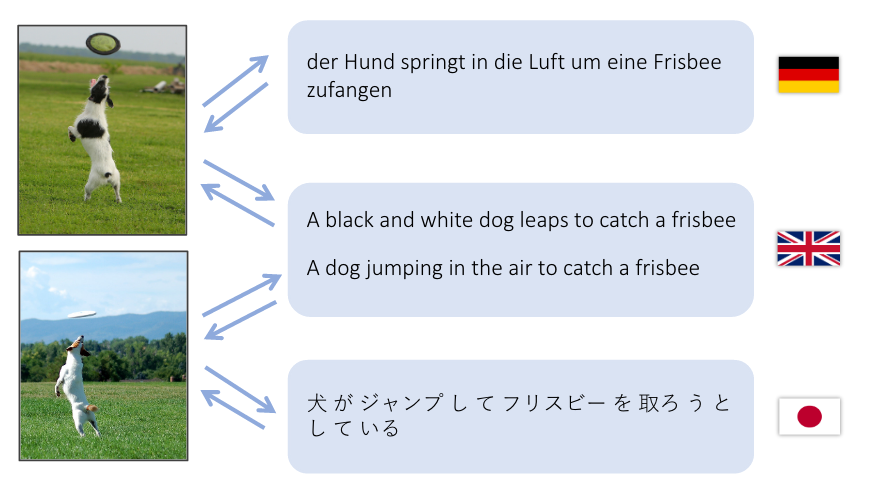
このデモは、英語の文を視覚的特徴空間へ、そしてドイツ語(Deutsch)と日本語(日本語)の両方の文へ翻訳しようとするものです。
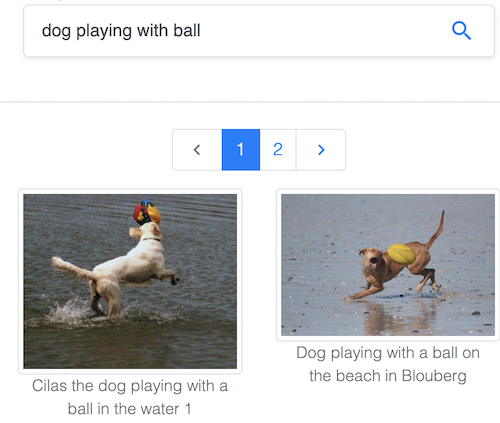
Flickr のキャプションが付いた100万枚の画像を持ち、数多くのプロジェクトで使われてきた SBU Captions データセットで、テキストから画像を検索します。
Common Visual Data Foundation が管理する人気のデータセット Common Objects in Context(COCO)で、テキストから画像を検索します。