FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Resumo do comunicado de imprensa
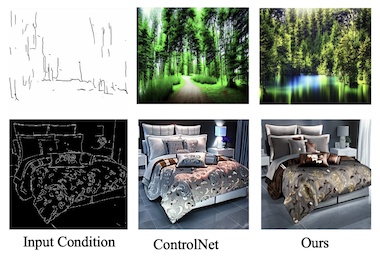
Pesquisadores da UC Santa Cruz, da Amazon, da UNC Chapel Hill, da Rice University e da UCLA desenvolveram uma forma mais eficiente de controlar geradores de imagens de IA usando múltiplos tipos de orientação visual simultaneamente. Modelos de difusão de texto para imagem atuais como o Stable Diffusion podem ser direcionados por entradas estruturais como mapas de bordas, mapas de profundidade e mapas de segmentação, mas treinar esses sistemas controláveis tipicamente exige recursos computacionais substanciais que crescem linearmente à medida que mais tipos de entrada são adicionados. O novo sistema da equipe, chamado FlexEControl, aborda isso tomando emprestada uma técnica matemática chamada decomposição de Kronecker da literatura mais ampla de aprendizado de máquina, usando-a para criar um conjunto compacto de pesos compartilhados que lida com diferentes modalidades de entrada em vez de aprender parâmetros separados para cada uma. O resultado é um modelo que usa 41% menos parâmetros treináveis e 30% menos memória do que um sistema comparável de ponta chamado UniControlNet, ao mesmo tempo em que reduz o tempo de treinamento por iteração de cerca de 5,7 segundos para 2,1 segundos. Para além da eficiência bruta, o FlexEControl também se sai melhor ao lidar com múltiplas entradas conflitantes ou redundantes — por exemplo, dois mapas de bordas diferentes da mesma cena — um cenário em que os métodos existentes tendem a produzir imagens confusas ou incoerentes. Os pesquisadores conseguiram isso adicionando duas funções de perda de treinamento especializadas que forçam o modelo a prestar atenção às regiões espaciais corretas e a alinhar suas saídas com os prompts textuais correspondentes. Em avaliações humanas, os anotadores preferiram as saídas do FlexEControl 64% das vezes em relação às do UniControlNet quando ambos os sistemas recebiam múltiplas entradas do mesmo tipo. O trabalho é relevante porque tornar a geração controlável de imagens mais barata e mais capaz de lidar com entradas complexas e mistas poderia ampliar de forma significativa o acesso a essas ferramentas para desenvolvedores e pesquisadores que trabalham com recursos computacionais limitados.
resumo
Modelos de difusão de texto para imagem (T2I) controláveis geram imagens condicionadas tanto a prompts textuais quanto a entradas semânticas de outras modalidades, como mapas de bordas. No entanto, os métodos T2I controláveis atuais comumente enfrentam desafios relacionados à eficiência e à fidelidade, especialmente ao condicionar a múltiplas entradas de uma mesma modalidade ou de modalidades diversas. Neste artigo, propomos um novo método Flexível e Eficiente, o FlexEControl, para a geração T2I controlável. No cerne do FlexEControl está uma estratégia única de decomposição de pesos, que permite a integração simplificada de vários tipos de entrada. Essa abordagem não apenas aprimora a fidelidade da imagem gerada ao controle, mas também reduz significativamente a sobrecarga computacional tipicamente associada ao condicionamento multimodal. Nossa abordagem alcança uma redução de 41% nos parâmetros treináveis e de 30% no uso de memória em comparação com o Uni-ControlNet. Além disso, ela dobra a eficiência de dados e pode gerar imagens de forma flexível sob a orientação de múltiplas condições de entrada de várias modalidades.
citação
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}