Learning from Synthetic Data for Visual Grounding
Resumo do comunicado de imprensa
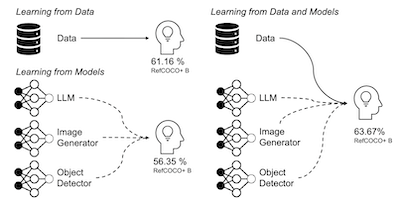
Pesquisadores da Rice University, da University of Maryland e da UC Irvine desenvolveram um pipeline chamado SynGround que gera automaticamente grandes volumes de dados de treinamento sintéticos para ajudar os sistemas de IA a conectar melhor descrições textuais a regiões específicas dentro de imagens — uma tarefa conhecida como ancoragem visual. O desafio que abordaram é que, embora pares imagem-texto possam ser coletados da web em escala, as anotações em nível de região necessárias para a ancoragem (bounding boxes que ligam frases a áreas da imagem) são caras e lentas de produzir manualmente; o conjunto de dados Visual Genome, um benchmark padrão, levou 33 mil trabalhadores seis meses para ser construído. O SynGround contorna esse gargalo encadeando vários modelos pré-treinados existentes: um grande modelo multimodal (LLaVA) descreve imagens reais em detalhe, essas descrições são alimentadas a um gerador de texto para imagem (Stable Diffusion) para criar imagens sintéticas, um LLM (Vicuna) extrai frases nominais curtas das descrições e um detector de objetos de vocabulário aberto (GLIP) desenha bounding boxes em torno dos objetos referenciados nas imagens sintéticas. Por meio de experimentos sistemáticos, a equipe descobriu que descrições de imagem detalhadas produzem imagens sintéticas muito melhores para essa tarefa do que a simples concatenação de texto ou resumos gerados por LLM, e que frases extraídas mais curtas funcionam melhor do que as mais longas. Quando usado para ajustar finamente dois modelos de visão e linguagem prontos para uso, ALBEF e BLIP, o SynGround melhorou a acurácia de localização em 4,81 e 17,11 pontos percentuais, respectivamente, nos benchmarks RefCOCO+ e Flickr30k; combinar os dados sintéticos com dados reais anotados elevou ainda mais o desempenho, superando o estado da arte anterior. O trabalho também mostrou que a abordagem pode funcionar com dependência mínima de imagens reais e escala de forma favorável com mais dados, sugerindo que pipelines sintéticos automatizados poderiam se tornar um substituto prático para a custosa anotação humana no treinamento de sistemas de ancoragem.
resumo
Este artigo investiga extensivamente a eficácia de dados de treinamento sintéticos para aprimorar as capacidades de modelos de visão e linguagem na ancoragem de descrições textuais a regiões de imagens. Exploramos várias estratégias para gerar da melhor forma pares imagem-texto e triplas imagem-texto-caixa usando uma série de modelos pré-treinados sob diferentes configurações e variados graus de dependência de dados reais. Por meio de análises comparativas com dados sintéticos, reais e coletados da web, identificamos fatores que contribuem para as diferenças de desempenho e propomos o SynGround, um pipeline eficaz para gerar dados sintéticos úteis para a ancoragem visual. Nossos achados mostram que o SynGround pode melhorar as capacidades de localização de modelos de visão e linguagem prontos para uso e oferece o potencial de geração de dados em escala arbitrariamente grande. Em particular, os dados gerados com o SynGround melhoram a acurácia no pointing game de modelos ALBEF e BLIP pré-treinados em 4,81% e 17,11% pontos percentuais absolutos, respectivamente, nos benchmarks RefCOCO+ e Flickr30k.
detalhes
citação
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o SynGround e qual problema ele aborda? O SynGround é um pipeline de dados sintéticos para ancoragem visual que gera triplas imagem-texto-caixa para reduzir a dependência de custosas anotações humanas de região.
- Como o SynGround gera dados de treinamento? Ele usa um modelo de descrição de imagens para produzir legendas detalhadas, um gerador de texto para imagem para sintetizar imagens, um LLM para extrair frases curtas de ancoragem e um detector de vocabulário aberto para produzir caixas para essas frases.
- Por que as legendas detalhadas são importantes no pipeline? Os experimentos mostram que legendas Image2Text detalhadas produzem imagens sintéticas mais úteis para a ancoragem do que a simples concatenação de legendas ou resumos Text2Text.
- Quanto o SynGround melhora a ancoragem visual? Os dados sintéticos do SynGround melhoram o ALBEF em 4,81 pontos percentuais e o BLIP em 17,11 pontos percentuais, em média, nas avaliações de pointing game do RefCOCO+ e do Flickr30k.
- O SynGround pode reduzir a dependência de imagens reais? Sim, o artigo relata variantes com muito menos dependência de imagens reais e mostra que os dados sintéticos superam dados comparáveis coletados da web para a ancoragem visual.
Principais contribuições
- O artigo fornece um estudo sistemático de como sintetizar dados imagem-texto e imagem-texto-caixa úteis para a ancoragem visual, em vez de apenas demonstrar uma receita de dados sintéticos.
- O SynGround combina modelos pré-treinados robustos de legendagem, geração de imagens, extração de frases e detecção de vocabulário aberto em um pipeline prático para uma supervisão de ancoragem escalável.
- Os experimentos identificam escolhas de design concretas que importam, incluindo descrições de imagem detalhadas para a geração e frases extraídas mais curtas para a supervisão de ancoragem.
- O artigo mostra que triplas sintéticas podem melhorar dois modelos de visão e linguagem diferentes, ALBEF e BLIP, apoiando a generalidade da abordagem para além de uma única arquitetura.
- A comparação com dados do Conceptual Captions coletados da web mostra que dados sintéticos direcionados podem ser mais eficazes para a ancoragem do que simplesmente escalar dados imagem-texto genéricos.
Limitações e ressalvas
- O SynGround herda algumas limitações dos geradores de legendas, geradores de imagens, LLMs e detectores pré-treinados que utiliza, mas isso também significa que o pipeline pode melhorar naturalmente à medida que esses modelos componentes se tornem mais robustos.
- As caixas e legendas sintéticas não correspondem plenamente à precisão e à diversidade das anotações humanas do Visual Genome, mas os ganhos de desempenho mostram que já são úteis o suficiente para reduzir substancialmente a pressão por anotações.
- Algumas pessoas ou cenas geradas podem conter artefatos visuais, o que é um problema conhecido da geração de imagens sintéticas; as melhorias na ancoragem sugerem que o pipeline permanece eficaz apesar de amostras ocasionalmente imperfeitas.
- O estudo foca principalmente na ancoragem visual no estilo pointing game com ALBEF e BLIP, deixando sistemas de predição de frase-caixa e arquiteturas multimodais mais recentes como alvos promissores de continuidade.
- O pipeline tem múltiplos estágios e escolhas de design, mas as ablações do artigo tornam essas escolhas interpretáveis e fornecem uma forte receita prática para futuros conjuntos de dados de ancoragem sintética.
Como interpretar este resultado
Este artigo é mais bem compreendido como um forte argumento empírico a favor da supervisão sintética na ancoragem visual: o SynGround mostra que triplas imagem-texto-caixa cuidadosamente geradas podem melhorar de forma significativa a localização, complementar dados reais e oferecer um caminho escalável para além da custosa anotação humana de região.