General Multi-label Image Classification with Transformers
News Release Summary
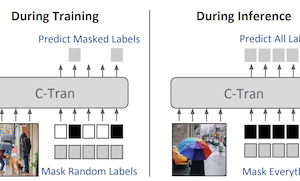
Researchers at the University of Virginia have developed a new deep learning system, called the Classification Transformer (C-Tran), that improves a computer's ability to identify multiple objects or concepts simultaneously within a single image — a task known as multi-label image classification. Unlike most existing approaches, which treat each label prediction largely in isolation or rely on predefined knowledge graphs to capture relationships between labels, C-Tran feeds both image features and label information jointly into a Transformer encoder, the same type of architecture that has driven recent advances in natural language processing. The key innovation is a training procedure called Label Mask Training, in which the model learns to predict randomly hidden labels given partial knowledge of the others, much like fill-in-the-blank exercises used to train language models such as BERT. This approach teaches the system to understand how labels relate to one another — for instance, that a fork and a knife tend to appear together — without needing hand-crafted rules. Beyond standard classification, C-Tran can also accept partial label information at inference time, meaning a user can tell the model that certain labels are definitively present or absent and receive more accurate predictions for the remaining unknowns. The system achieved state-of-the-art results on benchmark datasets including Microsoft COCO and Visual Genome, and also outperformed competing methods when tested with partially known or supplementary labels on four datasets. The practical significance is that real-world images often come with incomplete or contextual metadata — such as location tags or captions — and C-Tran is the first model designed to flexibly exploit that kind of partial evidence within a single unified framework.
abstract
Multi-label image classification is the task of predicting a set of labels corresponding to objects, attributes or other entities present in an image. In this work we propose the Classification Transformer (C-Tran), a general framework for multi-label image classification that leverages Transformers to exploit the complex dependencies among visual features and labels. Our approach consists of a Transformer encoder trained to predict a set of target labels given an input set of masked labels, and visual features from a convolutional neural network. A key ingredient of our method is a label mask training objective that uses a ternary encoding scheme to represent the state of the labels as positive, negative, or unknown during training. Our model shows state-of-the-art performance on challenging datasets such as COCO and Visual Genome. Moreover, because our model explicitly represents the uncertainty of labels during training, it is more general by allowing us to produce improved results for images with partial or extra label annotations during inference. We demonstrate this additional capability in the COCO, Visual Genome, News500, and CUB image datasets.
details
citation
@inproceedings{lanchantin2021general,
title = {General Multi-label Image Classification with Transformers},
author = {Lanchantin, Jack and Wang, Tianlu and Ordonez, Vicente and Qi, Yanjun},
year = {2021},
booktitle = {Conference on Computer Vision and Pattern Recognition CVPR 2021},
url = {https://arxiv.org/abs/2011.14027},
}