Feedback-prop: Convolutional Neural Network Inference under Partial Evidence
News Release Summary
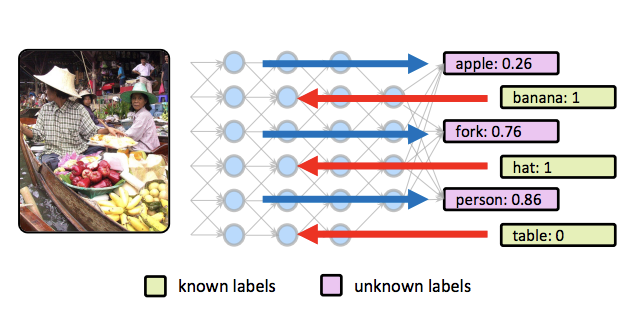
Researchers from the University of Virginia and CyberAgent have developed a technique that lets existing image-recognition neural networks make better predictions when some information about a photo is already known ahead of time. The method, called feedback-prop, addresses a gap between how computer vision systems are typically tested — using only visual input — and how they are often used in practice, where surrounding text, GPS data, user tags, or other contextual clues are frequently available. Rather than retraining a network to incorporate that extra information, the researchers found they could instead feed known labels back through a trained network during the inference step itself, adjusting the network's internal activations until predictions for the remaining unknown labels improved. They tested two variants of the approach — one that updates layers sequentially and one that injects small corrective variables at multiple layers simultaneously — across several tasks, including identifying objects in images when some labels are already known, predicting fine-grained scene categories when coarse categories are given, and generating image captions when object annotations are available. Across all tasks and multiple standard network architectures including VGG-16 and ResNet, adding partial evidence consistently improved accuracy, with relative gains ranging from roughly 10 to 13 percent depending on the task. Notably, the technique requires no changes to the original model's training and works with an arbitrary mix of known and unknown labels, making it broadly practical for real-world deployment scenarios where images rarely arrive without any accompanying context.
abstract
We propose an inference procedure for deep convolutional neural networks (CNNs) when partial evidence is available. Our method consists of a general feedback-based propagation approach (feedback-prop) that boosts the prediction accuracy for an arbitrary set of unknown target labels when the values for a non-overlapping arbitrary set of target labels are known. We show that existing models trained in a multi-label or multi-task setting can readily take advantage of feedback-prop without any retraining or fine-tuning. Our feedback-prop inference procedure is general, simple, reliable, and works on different challenging visual recognition tasks. We present two variants of feedback-prop based on layer-wise and residual iterative updates. We experiment using several multi-task models and show that feedback-prop is effective in all of them. Our results unveil a previously unreported but interesting dynamic property of deep CNNs. We also present an associated technical approach that takes advantage of this property for inference under partial evidence in general visual recognition tasks.
details
citation
@inproceedings{wang2018feedback,
title = {Feedback-prop: Convolutional Neural Network Inference under Partial Evidence},
author = {Wang, Tianlu and Yamaguchi, Kota and Ordonez, Vicente},
year = {2018},
booktitle = {Conference on Computer Vision and Pattern Recognition. CVPR 2018},
url = {https://arxiv.org/abs/1710.08049},
}