Chair Segments: A Compact Benchmark for the Study of Object Segmentation
Tóm tắt thông cáo báo chí
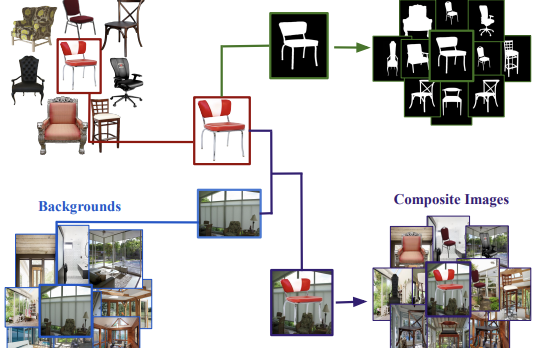
Các nhà nghiên cứu tại University of Virginia và các tổ chức hợp tác đã phát hành một bộ dữ liệu mới tên là Chair Segments, được thiết kế để cung cấp cho các nhà khoa học thị giác máy tính một cách nhanh hơn, rẻ hơn để kiểm tra các thuật toán phân đoạn ảnh. Vấn đề cốt lõi mà họ xác định là các bộ dữ liệu phân đoạn hiện có — như COCO hay PASCAL VOC — đều lớn, tốn kém để gán chú thích, và buộc các mô hình phải đồng thời xử lý nhận dạng đối tượng, định vị và tạo mặt nạ ở cấp độ pixel, khiến cho việc tách biệt và nhanh chóng lặp lại trên các ý tưởng riêng cho phân đoạn trở nên khó khăn. Để vượt qua điều này, nhóm đã xây dựng một bộ dữ liệu bán tổng hợp gồm khoảng 900 ảnh ghế với nền trong suốt, được ghép lên 10.000 ảnh cảnh trong nhà và ngoài trời đa dạng, tạo ra 50.000 ảnh ghép huấn luyện với các mặt nạ chuẩn (ground truth) chính xác đến từng pixel mà không cần bất kỳ chú thích thủ công nào. Các nhà nghiên cứu chọn ghế một cách có chủ đích: danh mục này nổi tiếng khó phân đoạn do có các bộ phận mảnh, rỗng và tự che khuất, và nó nằm trong số những danh mục khó nhất trong các benchmark hiện có. Các thí nghiệm của họ cho thấy một mô hình U-Net có thể được huấn luyện đến hội tụ hoàn toàn trên bộ dữ liệu trong khoảng 30 phút bằng một GPU đơn lẻ ở độ phân giải 64×64 — gần với mức độ phức tạp của CIFAR-10 cho phân loại — trong khi vẫn phân biệt được một cách có ý nghĩa giữa các kiến trúc mạnh hơn và yếu hơn. Quan trọng là, các mô hình được tiền huấn luyện trên Chair Segments rồi được tinh chỉnh trên bộ dữ liệu Object Discovery không liên quan (bao gồm xe hơi, ngựa và máy bay) đã đánh bại tất cả các phương pháp đã được công bố trước đây trên benchmark đó, cho thấy dữ liệu bán tổng hợp nắm bắt được những đặc trưng thực sự hữu ích của thế giới thực. Nhóm cũng xác nhận, lần đầu tiên trong phân đoạn, một mẫu hình trước đây từng được quan sát trong phân loại ảnh: các mô hình được tinh chỉnh từ cùng một bộ trọng số tiền huấn luyện thì tụ lại với nhau trong bề mặt tối ưu hóa và chuyển tiếp mượt mà giữa chúng, trong khi các mô hình được huấn luyện từ khởi tạo ngẫu nhiên thì không — một phát hiện có những hệ quả thực tiễn cho cách các mô hình phân đoạn có thể được khởi tạo và kết hợp thành tập hợp (ensemble).
tóm tắt
Qua nhiều năm, các bộ dữ liệu và benchmark đã có một ảnh hưởng vượt mức lên việc thiết kế các thuật toán mới. Trong bài báo này, chúng tôi giới thiệu ChairSegments, một bộ dữ liệu bán tổng hợp mới và gọn nhẹ cho phân đoạn đối tượng. Chúng tôi cũng trình bày những phát hiện thực nghiệm trong Transfer Learning phản ánh các phát hiện gần đây cho phân loại ảnh. Cụ thể, chúng tôi cho thấy rằng các mô hình được tinh chỉnh từ một tập trọng số đã được tiền huấn luyện nằm trong cùng một lòng chảo (basin) của bề mặt tối ưu hóa. ChairSegments bao gồm một tập đa dạng các ảnh ghế nguyên mẫu với nền trong suốt được ghép vào một mảng đa dạng các nền khác nhau. Chúng tôi hướng tới việc ChairSegments trở thành phiên bản tương đương của bộ dữ liệu CIFAR-10 nhưng dành cho việc nhanh chóng thiết kế và lặp lại trên các kiến trúc mô hình mới cho phân đoạn. Trên Chair Segments, một mô hình U-Net có thể được huấn luyện đến hội tụ hoàn toàn chỉ trong ba mươi phút bằng một GPU đơn lẻ. Cuối cùng, mặc dù bộ dữ liệu này là bán tổng hợp, nó có thể là một đại diện hữu ích cho dữ liệu thực, dẫn đến độ chính xác tốt nhất hiện nay trên bộ dữ liệu Object Discovery khi được dùng làm nguồn tiền huấn luyện.
chi tiết
trích dẫn
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}