FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
新闻稿摘要
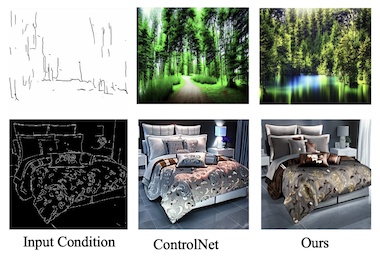
来自加州大学圣克鲁兹分校、Amazon、北卡罗来纳大学教堂山分校、莱斯大学和加州大学洛杉矶分校的研究人员开发了一种更高效的方法,可同时使用多种类型的视觉引导来控制 AI 图像生成器。当前的文本到图像扩散模型(如 Stable Diffusion)可以通过边缘图、深度图和分割图等结构化输入进行引导,但训练这些可控系统通常需要大量计算资源,并且随着输入类型的增加而线性增长。团队的新系统名为 FlexEControl,它借鉴了更广泛机器学习文献中一种称为 Kronecker 分解的数学技术来解决这一问题,利用它创建一组紧凑的共享权重来处理不同输入模态,而非为每种模态学习独立的参数。结果是该模型比领先的可比系统 UniControlNet 减少了 41% 的可训练参数和 30% 的内存,同时将每次迭代的训练时间从约 5.7 秒降至 2.1 秒。除了原始效率之外,FlexEControl 在处理多个相互冲突或冗余的输入时也表现更好——例如同一场景的两张不同边缘图——而现有方法在这种情况下往往会生成混乱或不连贯的图像。研究人员通过添加两个专门的训练损失函数实现了这一点,这些函数迫使模型关注正确的空间区域,并使其输出与相应的文本提示对齐。在人类评估中,当两个系统都被给予同类型的多个输入时,标注者有 64% 的时间更偏好 FlexEControl 的输出而非 UniControlNet 的输出。这项工作的意义在于,让可控图像生成更廉价、更能处理复杂的混合输入,可以切实地扩大计算资源有限的开发者和研究人员对这些工具的使用。
摘要
可控的文本到图像(T2I)扩散模型在文本提示和其他模态(如边缘图)的语义输入共同作用下生成图像。然而,当前的可控 T2I 方法普遍面临效率和保真度方面的挑战,尤其是在以来自相同或不同模态的多个输入为条件时。在本文中,我们提出了一种灵活高效的可控 T2I 生成方法 FlexEControl。FlexEControl 的核心是一种独特的权重分解策略,它允许各种输入类型的简化集成。该方法不仅增强了生成图像对控制的保真度,还显著降低了通常与多模态条件相关的计算开销。与 Uni-ControlNet 相比,我们的方法可训练参数减少了 41%,内存使用减少了 30%。此外,它将数据效率提升了一倍,并能够在多种模态的多个输入条件的引导下灵活生成图像。
引用
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}