Learning from Synthetic Data for Visual Grounding
新闻稿摘要
莱斯大学、马里兰大学和 UC Irvine 的研究人员开发了一个名为 SynGround 的流程,它能自动生成大量合成训练数据,帮助 AI 系统更好地将文本描述与图像中的特定区域相连接——这一任务被称为视觉定位。他们要解决的挑战在于:虽然图像-文本对可以从网络上大规模抓取,但定位所需的区域级标注(将短语与图像区域相连的边界框)却昂贵且产出缓慢;标准基准数据集 Visual Genome 动用了 33,000 名工作者耗时六个月才构建完成。SynGround 通过将若干现有的预训练模型串联起来绕开了这一瓶颈:一个大型多模态模型(LLaVA)为真实图像生成详细描述,这些描述被输入一个文本到图像生成器(Stable Diffusion)以创建合成图像,一个 LLM(Vicuna)从描述中提取简短名词短语,一个开放词汇目标检测器(GLIP)在合成图像中围绕被指代的物体绘制边界框。通过系统性实验,团队发现详细的图像描述比简单的文本拼接或 LLM 生成的摘要能为此任务产出好得多的合成图像,并且提取出的较短短语比较长短语效果更好。当用于微调两个现成的视觉语言模型 ALBEF 和 BLIP 时,SynGround 在 RefCOCO+ 和 Flickr30k 基准上分别将定位准确率提升了 4.81 和 17.11 个百分点;将合成数据与真实标注数据结合则进一步提升了性能,超越了此前的最先进水平。这项工作还表明,该方法能够在极少依赖真实图像的情况下运作,并随数据增多而良好扩展,意味着自动化合成流程有望成为训练定位系统时昂贵人工标注的实用替代。
摘要
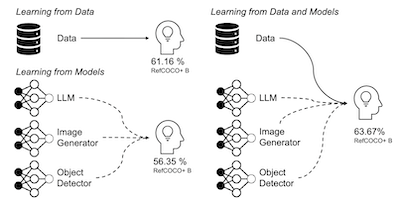
本文广泛研究了合成训练数据在提升视觉语言模型将文本描述定位到图像区域能力方面的有效性。我们探索了多种策略,借助一系列预训练模型,在不同设置下并以不同程度依赖真实数据,来最佳地生成图像-文本对和图像-文本-框三元组。通过与合成数据、真实数据和网络爬取数据的对比分析,我们识别出导致性能差异的因素,并提出 SynGround,一个用于生成有用的视觉定位合成数据的高效流程。我们的发现表明,SynGround 能够提升现成视觉语言模型的定位能力,并为任意大规模的数据生成提供了潜力。特别地,用 SynGround 生成的数据在 RefCOCO+ 和 Flickr30k 基准上分别将预训练 ALBEF 和 BLIP 模型的 pointing game 准确率提升了 4.81% 和 17.11% 的绝对百分点。
详情
引用
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 SynGround,它解决了什么问题?SynGround 是一个用于视觉定位的合成数据流程,它生成图像-文本-框三元组,以减少对昂贵人工区域标注的依赖。
- SynGround 如何生成训练数据?它使用一个图像描述模型生成详细描述,一个文本到图像生成器合成图像,一个 LLM 提取简短的定位短语,以及一个开放词汇检测器为这些短语生成框。
- 为什么详细描述在该流程中很重要?实验表明,详细的 Image2Text 描述比简单的描述拼接或 Text2Text 摘要能为定位产出更有用的合成图像。
- SynGround 对视觉定位的提升有多大?来自 SynGround 的合成数据在 RefCOCO+ 和 Flickr30k 的 pointing-game 评估中,平均将 ALBEF 提升 4.81 个百分点、将 BLIP 提升 17.11 个百分点。
- SynGround 能否减少对真实图像的依赖?可以,论文报告了远更少依赖真实图像的变体,并表明合成数据在视觉定位上优于可比的网络爬取数据。
主要贡献
- 论文系统地研究了如何为视觉定位合成有用的图像-文本和图像-文本-框数据,而不仅仅是展示一种合成数据配方。
- SynGround 将用于描述生成、图像生成、短语提取和开放词汇检测的强大预训练模型组合成一个可扩展定位监督的实用流程。
- 实验识别出了若干关键的设计选择,包括用于生成的详细图像描述以及用于定位监督的较短提取短语。
- 论文表明,合成三元组能够改善两个不同的视觉语言模型 ALBEF 和 BLIP,支持了该方法超越单一架构的通用性。
- 与 Conceptual Captions 网络爬取数据的比较表明,针对性的合成数据对于定位而言可能比单纯扩大通用图像-文本数据更有效。
局限与注意事项
- SynGround 从其所用的预训练描述模型、图像生成器、LLM 和检测器那里继承了一些局限,但这也意味着随着这些组件模型变强,该流程能自然地得到改进。
- 合成的框和描述未能完全匹配人工 Visual Genome 标注的精度和多样性,但性能增益表明它们已经足够有用,可大幅减轻标注压力。
- 某些生成的人物或场景可能包含视觉伪影,这是合成图像生成的已知问题;定位上的改善表明,尽管偶有不完美样本,该流程仍然有效。
- 该研究主要聚焦于使用 ALBEF 和 BLIP 的 pointing-game 式视觉定位,将短语-框预测系统和更新的多模态架构留作有前景的后续目标。
- 该流程包含多个阶段和设计选择,但论文的消融实验使这些选择变得可解释,并为未来的合成定位数据集提供了一个有力的实用配方。
如何理解这一结果
这篇论文最好被理解为对视觉定位中合成监督的有力实证论证:SynGround 表明,精心生成的图像-文本-框三元组能够显著改善定位、增强真实数据,并提供一条超越昂贵人工区域标注的可扩展途径。