Diese Demo versucht, Bereiche eines Bildes hervorzuheben, die durch einen beliebigen Eingabetext bestimmt werden.
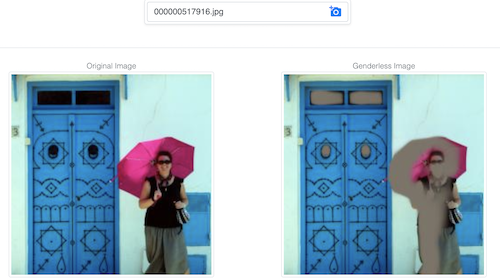
Diese Demo versucht, es einem Modell zu erschweren, das Geschlecht aus einem Bild vorherzusagen, indem sie das Bild so verändert, dass diese Aufgabe schwieriger wird, während der Großteil der Bildinformation erhalten bleibt.
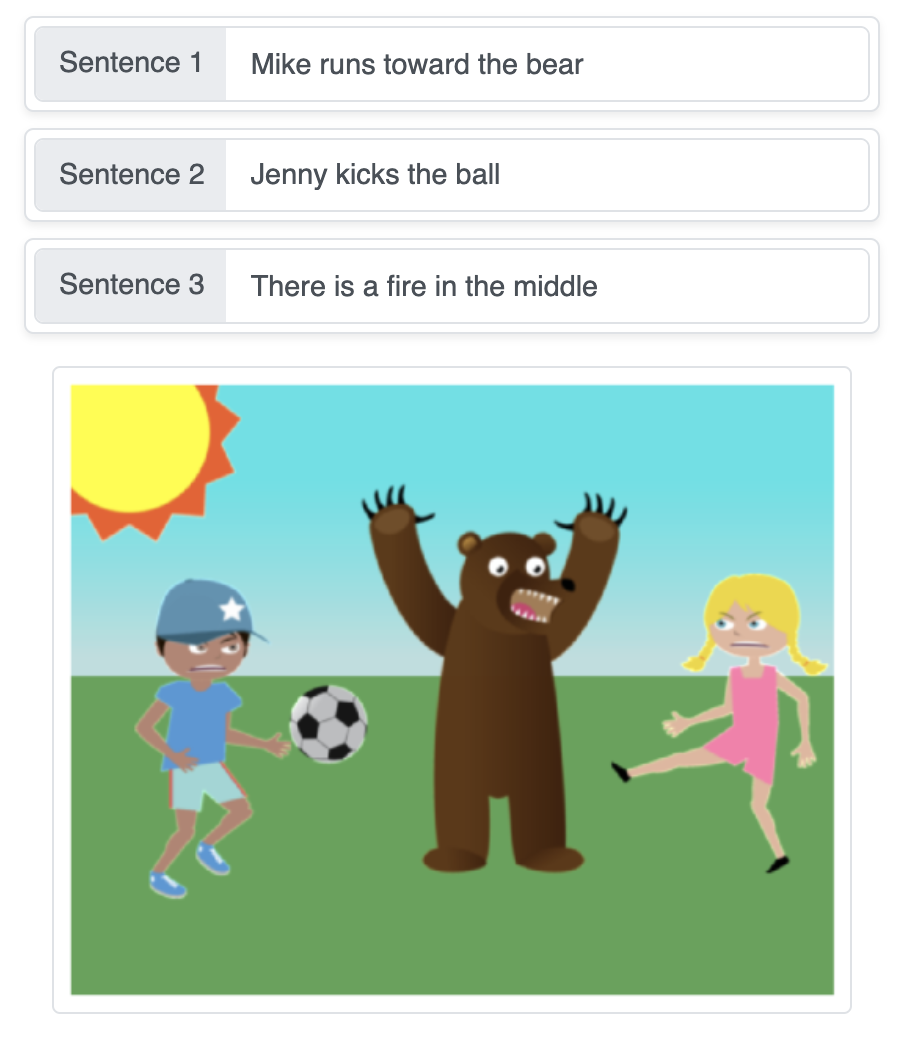
Diese Demo verwandelt textuelle Beschreibungen in eine automatisch erzeugte Szene, indem sie Objekte Schritt für Schritt nacheinander auf einem einfarbigen Hintergrund zusammensetzt und dabei neuronale Netze zur Sequenzgenerierung verwendet.
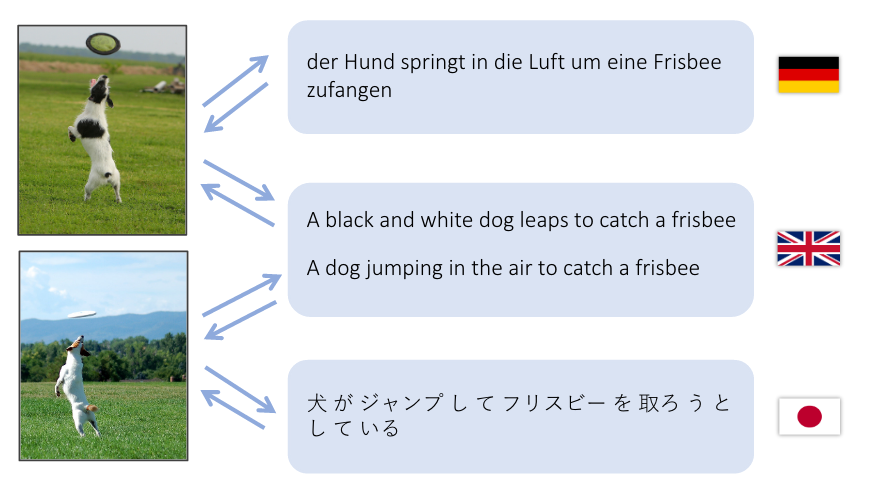
Diese Demo versucht, einen englischen Satz in einen visuellen Merkmalsraum sowie in einen Satz sowohl auf Deutsch (Deutsch) als auch auf Japanisch (日本語) zu übersetzen.
Durchsuchen Sie Bilder per Text im SBU Captions Dataset, das 1 Million Bilder mit Bildunterschriften von Flickr enthält und in zahlreichen Projekten verwendet wurde.
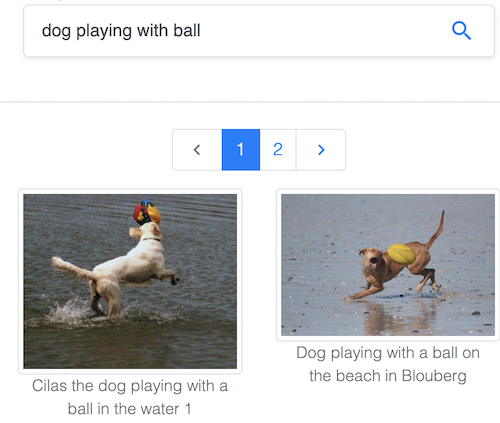
Durchsuchen Sie Bilder per Text im beliebten Datensatz Common Objects in Context (COCO), der von der Common Visual Data Foundation gepflegt wird.