本演示尝试根据任意输入文本高亮图像中的相关区域。
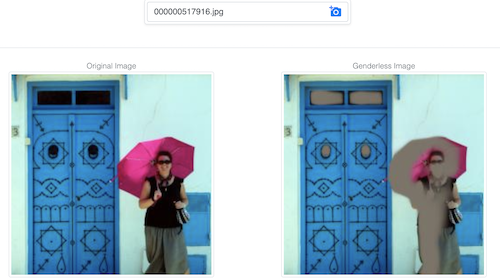
本演示尝试通过修改图像,使模型难以从中预测性别,同时尽量保留图像的大部分信息。
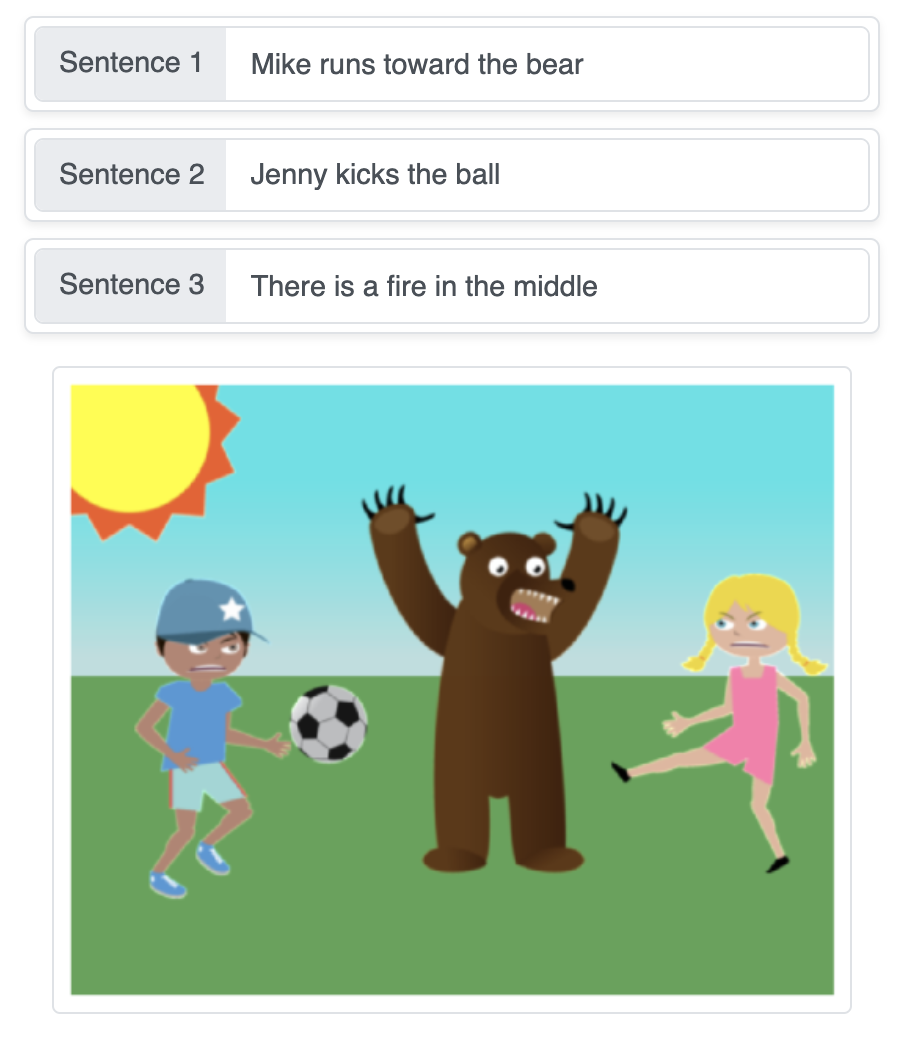
本演示利用序列生成神经网络,逐步将物体依次拼接到纯色背景上,从而将文本描述自动生成为一幅场景。
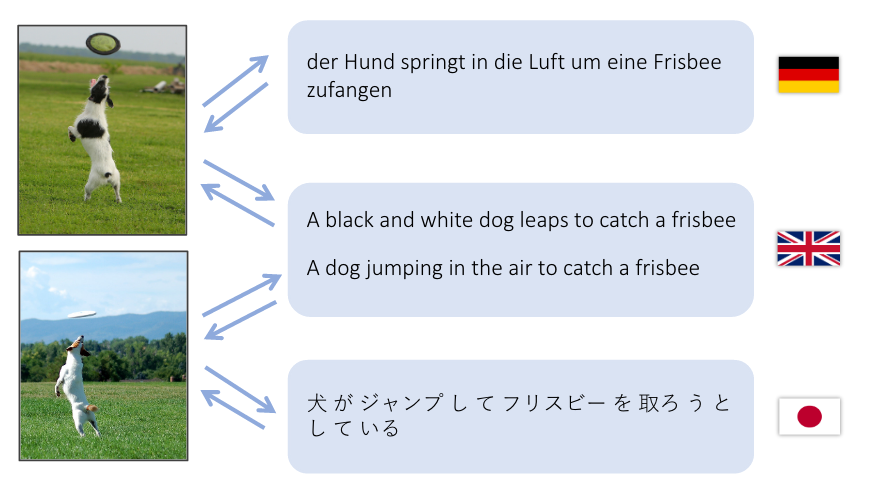
本演示尝试将一句英文翻译到视觉特征空间,并翻译成德语(Deutsch)和日语(日本語)两种语言的句子。
在 SBU Captions 数据集中按文本搜索图像。该数据集包含 100 万张来自 Flickr 的带字幕图像,已被广泛应用于众多项目。
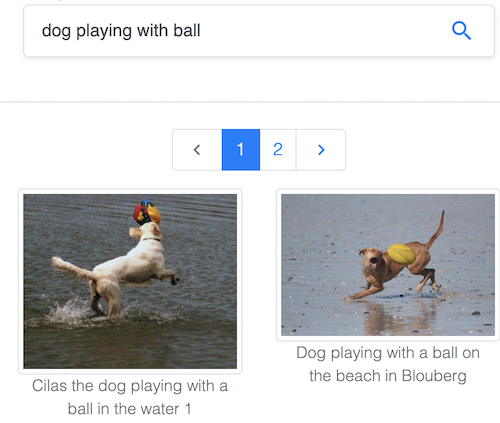
在由 Common Visual Data Foundation 维护的热门 Common Objects in Context(COCO)数据集中按文本搜索图像。