Esta demo tenta destacar áreas de uma imagem condicionadas por um texto de entrada arbitrário.
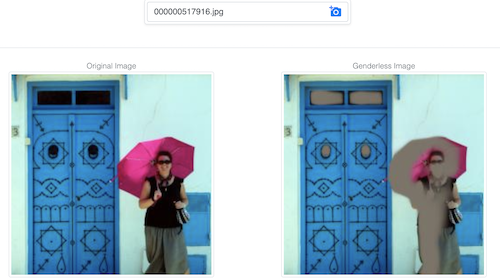
Esta demo tenta dificultar que um modelo preveja o gênero a partir de uma imagem, modificando-a para que essa tarefa se torne mais difícil, preservando a maior parte da informação da imagem.
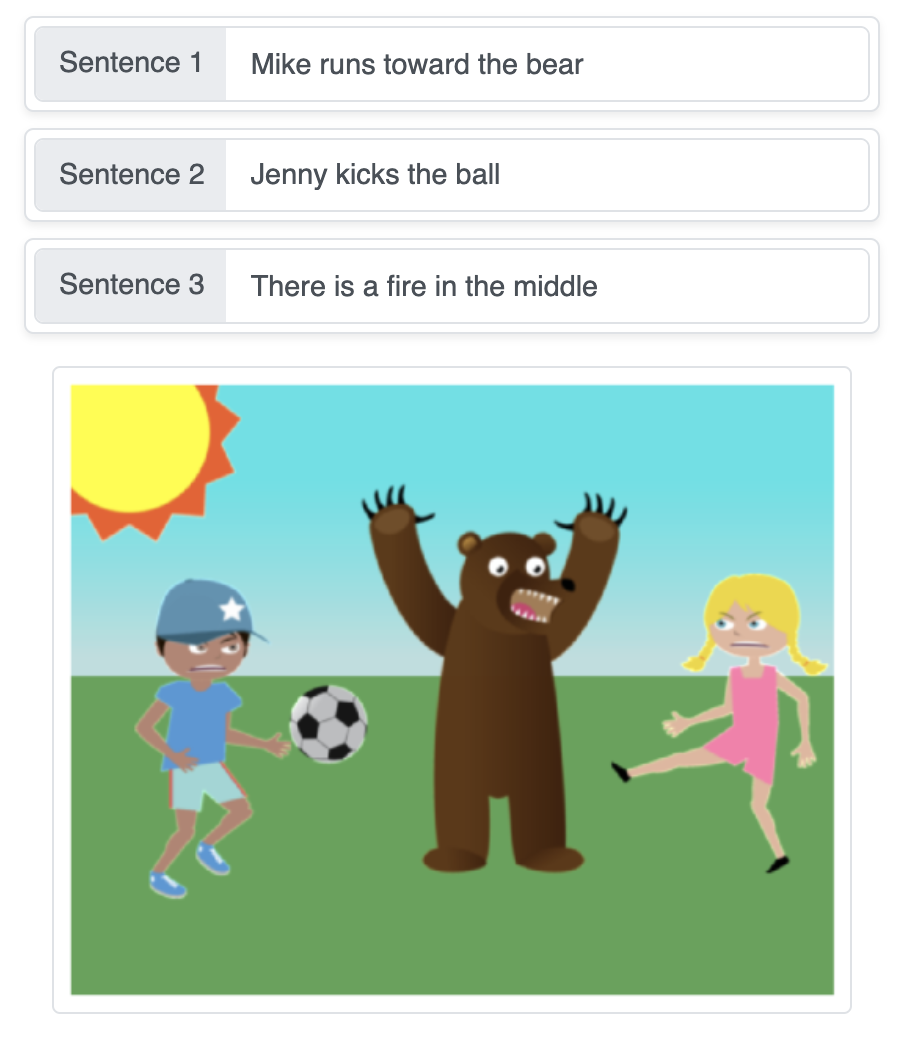
Esta demo transforma descrições textuais em uma cena gerada automaticamente, posicionando objetos sequencialmente sobre um fundo liso, passo a passo, usando redes neurais de geração de sequências.
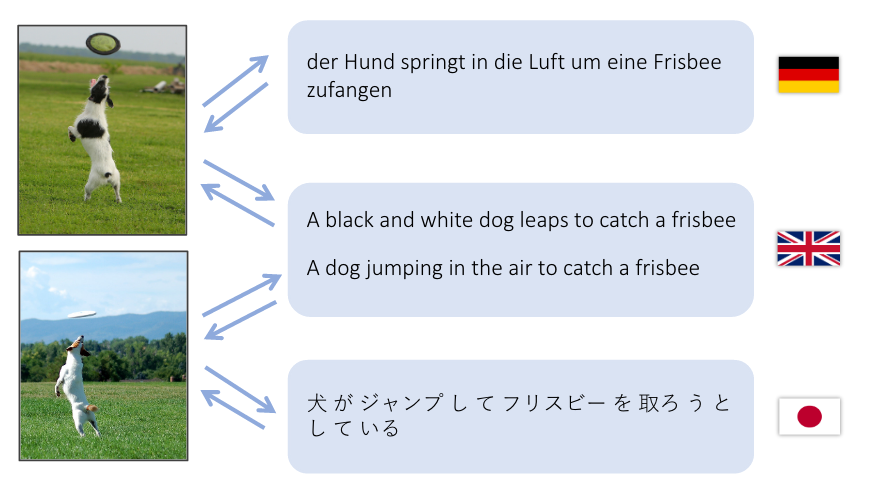
Esta demo tenta traduzir uma frase em inglês para um espaço de características visuais e para uma frase tanto em alemão (Deutsch) quanto em japonês (日本語).
Pesquise imagens por texto no conjunto de dados SBU Captions, que possui 1 milhão de imagens com legendas do Flickr e tem sido usado em diversos projetos.
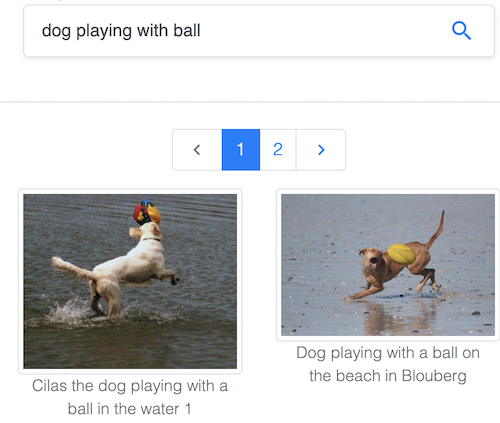
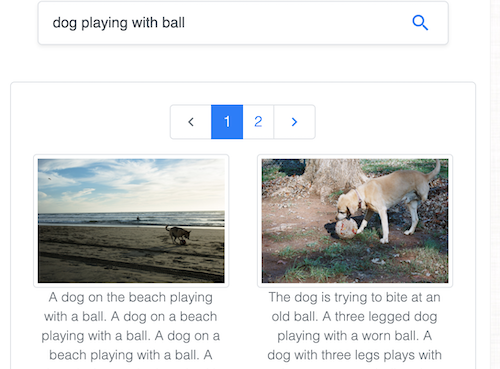
Pesquise imagens por texto no popular conjunto de dados Common Objects in Context (COCO), mantido pela Common Visual Data Foundation.