이 데모는 임의의 입력 텍스트를 기반으로 이미지의 영역을 강조 표시합니다.
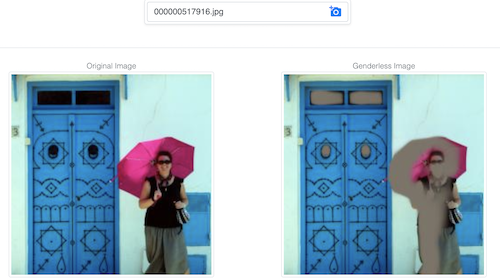
이 데모는 이미지의 대부분 정보를 유지하면서도 모델이 이미지에서 성별을 예측하기 어렵도록 이미지를 수정합니다.
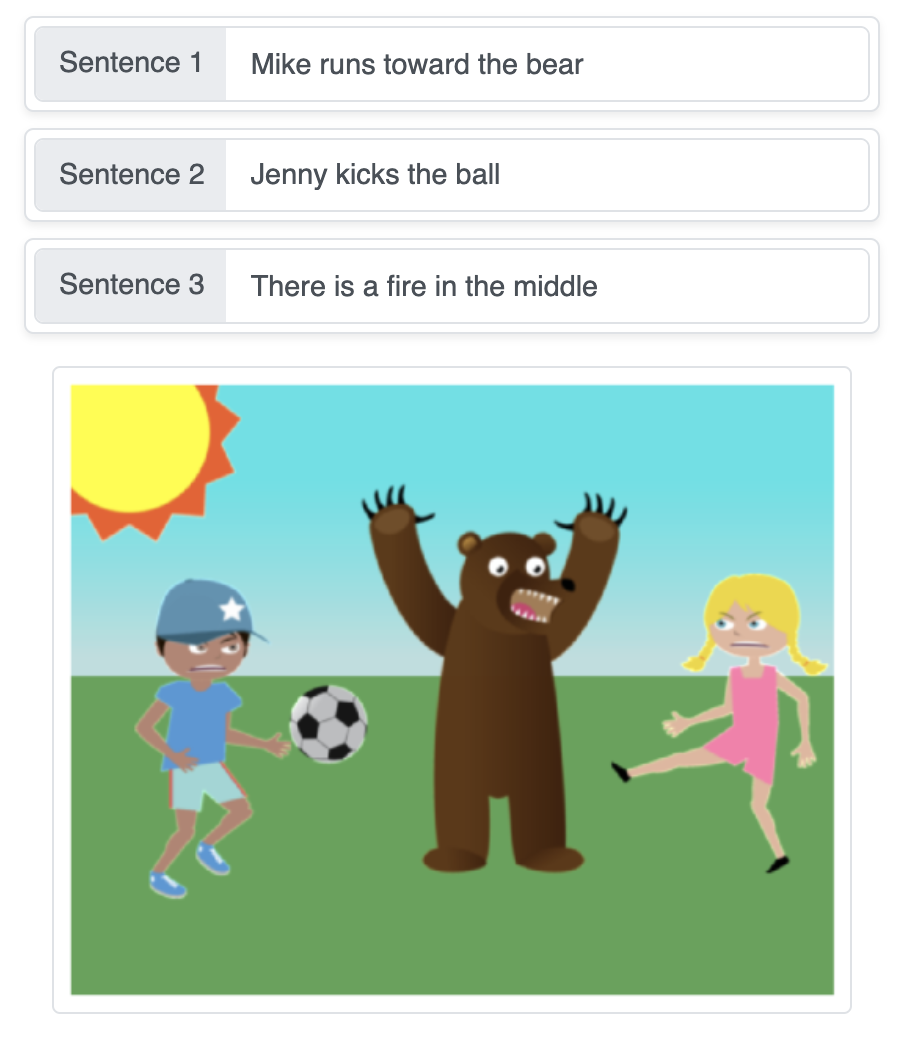
이 데모는 시퀀스 생성 신경망을 사용하여 객체를 빈 배경 위에 단계별로 순차적으로 배치함으로써 텍스트 설명을 자동으로 생성된 장면으로 변환합니다.
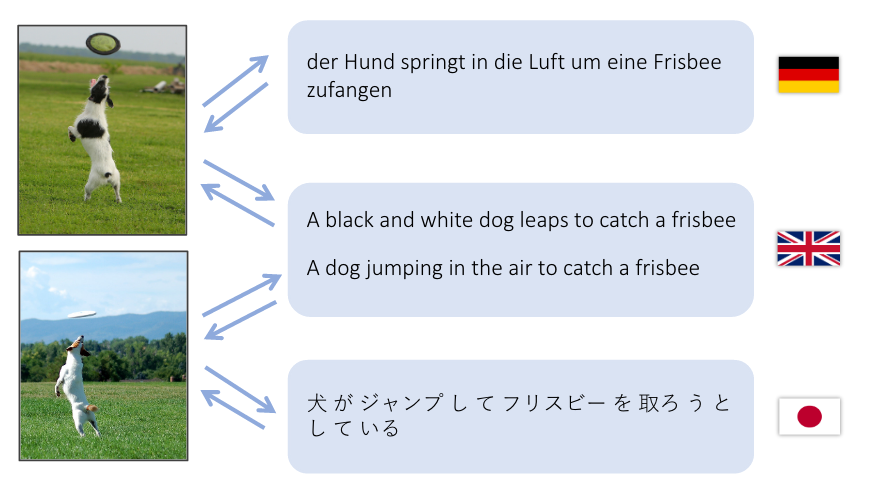
이 데모는 영어 문장을 시각적 특징 공간으로, 그리고 독일어(Deutsch)와 일본어(日本語) 문장으로 번역합니다.
Flickr의 캡션이 달린 100만 장의 이미지를 포함하며 수많은 프로젝트에 사용된 SBU Captions 데이터셋에서 텍스트로 이미지를 검색하세요
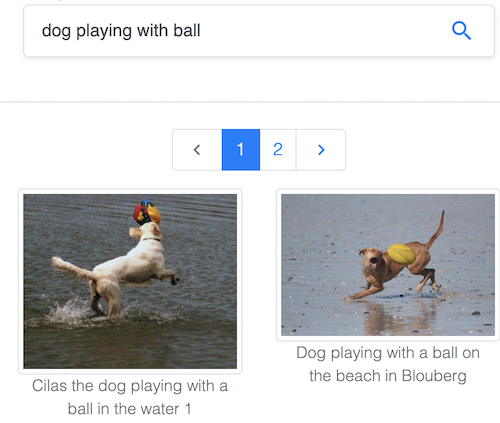
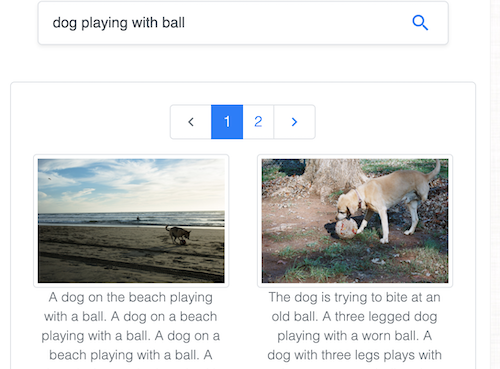
Common Visual Data Foundation이 관리하는 인기 있는 Common Objects in Context(COCO) 데이터셋에서 텍스트로 이미지를 검색하세요.