Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Zusammenfassung der Pressemitteilung
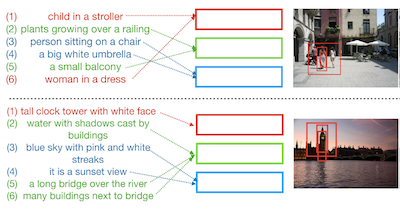
Forscher der University of Virginia und von IBM Research haben ein System namens Drill-down entwickelt, das es Nutzern ermöglicht, bestimmte Bilder zu finden, indem sie eine Reihe von Beschreibungen in natürlicher Sprache eingeben, von denen jede die Suche weiter eingrenzt, anstatt zu versuchen, alles in einer einzigen Anfrage zu erfassen. Das Problem, das sie angingen, ist ein bekanntes: Bestehende Bildsuchwerkzeuge tun sich schwer, wenn ein Nutzer ein sehr bestimmtes Foto einer komplexen Szene mit mehreren Objekten finden möchte, denn eine vollständige Szenenbeschreibung in einen einzigen Satz zu pressen, ist sowohl schwierig als auch ungenau. Anstatt diesen Einzelschuss-Ansatz zu erzwingen, lässt Drill-down Nutzer breit beginnen — etwa "eine Gruppe von Menschen, die in einem Park posieren" — und über mehrere Runden hinweg schrittweise spezifischere Details hinzufügen, etwa "unter ihnen ist eine Braut", wobei das System seine Ergebnisse jedes Mal aktualisiert. Der zentrale technische Beitrag ist eine kompakte Menge von Zustandsvektoren, die die Historie der Anfragen eines Nutzers speichern und organisieren, wobei jeder Vektor lernt, einen eigenständigen Teil der Szene zu verfolgen, anstatt alles in eine einzige Repräsentation zusammenzufassen, wie es bei früheren dialogbasierten Retrieval-Systemen funktionierte. Entscheidend ist, dass das Team feststellte, dass es das Modell trainieren konnte, ohne aufwendige, von Menschen annotierte Suchsitzungen zu sammeln, und stattdessen bestehende Bildregionsbeschriftungen aus dem Visual Genome-Datensatz als kostengünstigen Ersatz für echte Nutzeranfragen verwendete. Tests sowohl mit simulierten als auch mit echten menschlichen Nutzern zeigten, dass Drill-down konkurrierende Methoden übertraf und dabei tatsächlich weniger Speicher und weniger Parameter verwendete, und mehr als 80 Prozent der menschlichen Tester fanden ihr Zielbild innerhalb von fünf Runden erfolgreich. Die Arbeit legt nahe, dass das Aufteilen der Bildsuche in ein dialogartiges Hin und Her ein praktikabler Weg ist, um hochspezifische Bilder in großen, vielfältigen Sammlungen abzurufen.
Zusammenfassung
Diese Arbeit untersucht die Aufgabe des interaktiven Image Retrievals mit Anfragen in natürlicher Sprache, bei dem ein Nutzer schrittweise Eingabeanfragen bereitstellt, um eine Menge von Retrieval-Ergebnissen zu verfeinern. Darüber hinaus untersucht unsere Arbeit dieses Problem im Kontext komplexer Bildszenen, die mehrere Objekte enthalten. Wir schlagen Drill-down vor, ein wirksames Framework zur Kodierung mehrerer Anfragen mit einer effizienten kompakten Zustandsrepräsentation, das aktuelle Methoden für das einrundige Image Retrieval erheblich erweitert. Wir zeigen, dass die Verwendung mehrerer Runden von Anfragen in natürlicher Sprache als Eingabe überraschend wirksam sein kann, um beliebig spezifische Bilder komplexer Szenen zu finden. Darüber hinaus stellen wir fest, dass bestehende Bilddatensätze mit textuellen Bildunterschriften eine überraschend wirksame Form der schwachen Überwachung für diese Aufgabe bieten können. Wir vergleichen unsere Methode mit bestehenden sequenziellen Kodierungs- und Embedding-Netzen und demonstrieren eine überlegene Leistung auf zwei vorgeschlagenen Benchmarks: automatisches Image Retrieval in einem simulierten Szenario, das Regionsbeschriftungen als Anfragen verwendet, und interaktives Image Retrieval unter Verwendung echter Anfragen von menschlichen Bewertern.
Details
Zitation
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}