プレスリリース要約
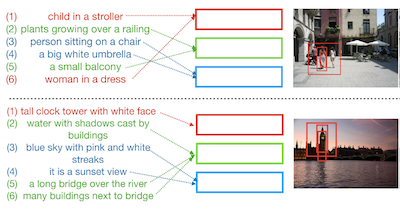
バージニア大学とIBM Researchの研究者らは、ユーザーが一連の自然言語による説明を入力することで特定の画像を見つけられる、Drill-downと呼ばれるシステムを開発した。各説明は単一のクエリですべてを捉えようとするのではなく、検索をさらに絞り込んでいくものである。彼らが取り組んでいた問題はおなじみのものである。すなわち、シーン全体の説明を1つの文に詰め込むことは困難で不正確でもあるため、ユーザーが複数の物体を含む複雑なシーンの非常に特定の写真を見つけようとすると、既存の画像検索ツールは苦戦する。その単発のアプローチを強いるのではなく、Drill-downはユーザーが大まかに(例えば「公園でポーズをとっている人々の集団」と)始め、複数のターンにわたって「その中に花嫁がいる」といったより具体的な詳細を段階的に追加していくことを可能にし、システムは毎回その結果を更新する。重要な技術的貢献は、ユーザーのクエリの履歴を保存し整理するコンパクトな状態ベクトルの集合であり、各ベクトルはすべてを1つの表現に集約するのではなく、シーンの異なる部分を追跡することを学習する。これは初期の対話ベースの検索システムが機能していた方法である。決定的に重要なことに、チームは高価な人手によるアノテーション付きの検索セッションを収集することなくモデルを訓練できることを見出し、その代わりにVisual Genomeデータセットの既存の画像領域キャプションを実際のユーザークエリの安価な代替として用いた。シミュレートされたユーザーと実際の人間のユーザーの両方でのテストにより、Drill-downは実際にはより少ないメモリと少ないパラメータを使いながら競合手法を上回り、人間のテスターの80パーセント超が5ターン以内に目標の画像を正常に見つけ出したことが示された。この研究は、画像検索を会話的なやり取りに分解することが、大規模で多様なコレクションの中から非常に特定の画像を検索するための実用的な道であることを示唆している。
要旨
本論文では、ユーザーが検索結果の集合を絞り込むために段階的に入力クエリを与える、自然言語クエリを用いた対話的画像検索のタスクを探究する。さらに、本研究では、複数の物体を含む複雑な画像シーンの文脈においてこの問題を探究する。我々は、単一ラウンドの画像検索のための現行手法を大幅に拡張する、効率的でコンパクトな状態表現を用いて複数のクエリを符号化する効果的なフレームワークであるDrill-downを提案する。複数ラウンドの自然言語クエリを入力として用いることが、複雑なシーンの任意に特定された画像を見つけるうえで驚くほど効果的でありうることを示す。さらに、テキストキャプション付きの既存の画像データセットが、このタスクに対して驚くほど効果的な弱教師の形態を提供しうることを見出す。我々は本手法を既存の逐次符号化ネットワークおよび埋め込みネットワークと比較し、提案する2つのベンチマーク、すなわち領域キャプションをクエリとして用いるシミュレートされたシナリオでの自動画像検索と、人間の評価者からの実際のクエリを用いた対話的画像検索において、優れた性能を実証する。
詳細
引用
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}