Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Resumo do comunicado de imprensa
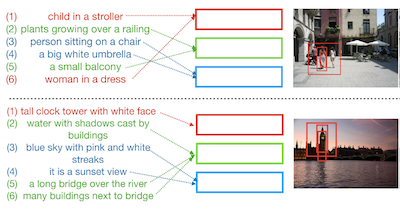
Pesquisadores da University of Virginia e da IBM Research desenvolveram um sistema chamado Drill-down que permite aos usuários encontrar imagens específicas digitando uma série de descrições em linguagem natural, cada uma estreitando ainda mais a busca, em vez de tentar capturar tudo em uma única consulta. O problema que estavam enfrentando é familiar: as ferramentas de busca de imagens existentes têm dificuldade quando um usuário quer localizar uma foto muito específica de uma cena complexa contendo múltiplos objetos, porque comprimir a descrição de uma cena inteira em uma única frase é tanto difícil quanto impreciso. Em vez de impor essa abordagem de tentativa única, o Drill-down permite que os usuários comecem de forma ampla — digamos, "um grupo de pessoas posando em um parque" — e adicionem progressivamente detalhes mais específicos ao longo de várias rodadas, como "há uma noiva entre elas", com o sistema atualizando seus resultados a cada vez. A principal contribuição técnica é um conjunto compacto de vetores de estado que armazenam e organizam o histórico das consultas de um usuário, com cada vetor aprendendo a rastrear uma parte distinta da cena, em vez de colapsar tudo em uma única representação, que era como os sistemas de recuperação baseados em diálogo anteriores funcionavam. Crucialmente, a equipe descobriu que poderia treinar o modelo sem coletar sessões de busca anotadas por humanos, que são caras, usando em vez disso legendas de regiões de imagens já existentes do conjunto de dados Visual Genome como um substituto barato para consultas reais de usuários. Testes com usuários simulados e reais mostraram que o Drill-down superou métodos concorrentes ao mesmo tempo em que usava menos memória e menos parâmetros, e mais de 80 por cento dos testadores humanos localizaram com sucesso sua imagem-alvo em cinco rodadas. O trabalho sugere que dividir a busca de imagens em um vai e vem conversacional é um caminho prático para recuperar imagens altamente específicas em coleções grandes e diversas.
resumo
Este artigo explora a tarefa de recuperação interativa de imagens usando consultas em linguagem natural, na qual um usuário fornece consultas de entrada progressivamente para refinar um conjunto de resultados de recuperação. Além disso, nosso trabalho explora esse problema no contexto de cenas de imagens complexas contendo múltiplos objetos. Propomos o Drill-down, um framework eficaz para codificar múltiplas consultas com uma representação de estado compacta e eficiente que estende significativamente os métodos atuais de recuperação de imagens em rodada única. Mostramos que usar múltiplas rodadas de consultas em linguagem natural como entrada pode ser surpreendentemente eficaz para encontrar imagens arbitrariamente específicas de cenas complexas. Além disso, constatamos que conjuntos de dados de imagens existentes com legendas textuais podem fornecer uma forma surpreendentemente eficaz de supervisão fraca para essa tarefa. Comparamos nosso método com redes existentes de codificação sequencial e de embedding, demonstrando desempenho superior em dois benchmarks propostos: recuperação automática de imagens em um cenário simulado que usa legendas de regiões como consultas, e recuperação interativa de imagens usando consultas reais de avaliadores humanos.
detalhes
citação
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}