Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Sintesi del comunicato stampa
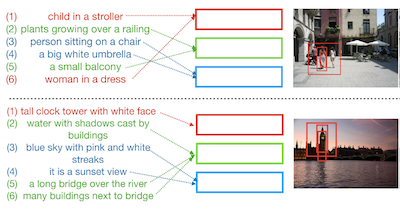
I ricercatori della University of Virginia e di IBM Research hanno sviluppato un sistema chiamato Drill-down che consente agli utenti di trovare immagini specifiche digitando una serie di descrizioni in linguaggio naturale, ciascuna delle quali restringe ulteriormente la ricerca invece di cercare di catturare tutto in un'unica query. Il problema affrontato è familiare: gli strumenti di ricerca di immagini esistenti faticano quando un utente vuole individuare una foto molto particolare di una scena complessa contenente più oggetti, perché racchiudere l'intera descrizione di una scena in una sola frase è al tempo stesso difficile e impreciso. Anziché imporre quell'approccio a colpo singolo, Drill-down consente agli utenti di iniziare in modo ampio — poniamo, "un gruppo di persone in posa in un parco" — e di aggiungere progressivamente dettagli più specifici nell'arco di vari turni, come "tra loro c'è una sposa", con il sistema che aggiorna i risultati a ogni passaggio. Il contributo tecnico chiave è un insieme compatto di vettori di stato che memorizzano e organizzano la cronologia delle query di un utente, con ciascun vettore che impara a tracciare una parte distinta della scena anziché far collassare tutto in un'unica rappresentazione, come funzionavano i precedenti sistemi di recupero basati sul dialogo. Soprattutto, il team ha scoperto di poter addestrare il modello senza raccogliere costose sessioni di ricerca annotate da esseri umani, utilizzando invece le didascalie di regione di immagini esistenti del dataset Visual Genome come sostituto economico delle query reali degli utenti. I test su utenti sia simulati sia umani reali hanno mostrato che Drill-down ha superato i metodi concorrenti utilizzando in realtà meno memoria e meno parametri, e oltre l'80 percento dei tester umani ha individuato con successo la propria immagine bersaglio entro cinque turni. Il lavoro suggerisce che scomporre la ricerca di immagini in un dialogo a botta e risposta è una via pratica per recuperare immagini altamente specifiche in raccolte ampie e diversificate.
abstract
Questo articolo esplora il compito del recupero interattivo di immagini tramite query in linguaggio naturale, in cui un utente fornisce progressivamente query in input per affinare un insieme di risultati di recupero. Inoltre, il nostro lavoro esplora questo problema nel contesto di scene di immagini complesse contenenti più oggetti. Proponiamo Drill-down, un framework efficace per codificare più query con una rappresentazione dello stato compatta ed efficiente che estende in modo significativo i metodi attuali per il recupero di immagini a singolo turno. Mostriamo che l'utilizzo di più turni di query in linguaggio naturale come input può essere sorprendentemente efficace per trovare immagini arbitrariamente specifiche di scene complesse. Inoltre, riscontriamo che i dataset di immagini esistenti con didascalie testuali possono fornire una forma sorprendentemente efficace di supervisione debole per questo compito. Confrontiamo il nostro metodo con le reti esistenti di codifica sequenziale ed embedding, dimostrando prestazioni superiori su due benchmark proposti: il recupero automatico di immagini in uno scenario simulato che utilizza le didascalie di regione come query e il recupero interattivo di immagini tramite query reali fornite da valutatori umani.
dettagli
citazione
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}