Improved Visual Grounding through Self-Consistent Explanations
Resumen de prensa
Investigadores de la Universidad Rice y la Universidad de California en Irvine han desarrollado una técnica para ayudar a los sistemas de IA a localizar de forma más fiable la ubicación de objetos en imágenes a partir de una descripción de texto, una tarea conocida como grounding visual. El problema central que abordaron es que los modelos de visión-lenguaje existentes, que aprenden a emparejar imágenes con texto, pueden localizar correctamente un objeto como un "frisbee" pero fallan cuando el mismo objeto se describe usando una palabra diferente, como "disco". Para solucionarlo, el equipo creó un enfoque de entrenamiento llamado SelfEQ (Self-consistency EQuivalence Tuning), que usa un gran modelo de lenguaje para generar automáticamente paráfrasis de los pies de imagen y luego ajusta el modelo visual de modo que tanto la frase original como su paráfrasis produzcan la misma región resaltada en la imagen. El método funciona sin requerir ninguna anotación de caja delimitadora, apoyándose en cambio en mapas de explicación visual basados en gradientes —específicamente GradCAM— como una forma de supervisión débil. Probado en tres benchmarks estándar, SelfEQ mejoró la precisión de localización en 4,69 puntos porcentuales en Flickr30k, 7,68 puntos en ReferIt y un promedio de 3,74 puntos en RefCOCO+, superando a la mayoría de los otros métodos que también prescinden de la supervisión por cajas delimitadoras e incluso rivalizando con algunos que la usan. La consecuencia práctica es un modelo que maneja un vocabulario más amplio y localiza objetos de forma más consistente, un avance útil para aplicaciones como la búsqueda visual y la interacción humano-máquina que dependen de conectar el lenguaje con partes específicas de una imagen.
resumen
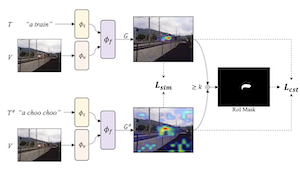
Los modelos de visión y lenguaje entrenados para emparejar imágenes con texto pueden combinarse con métodos de explicación visual para señalar las ubicaciones de objetos específicos en una imagen. Nuestro trabajo muestra que las capacidades de localización —"grounding"— de estos modelos pueden mejorarse aún más mediante el ajuste fino para obtener explicaciones visuales autoconsistentes. Proponemos una estrategia para aumentar los conjuntos de datos texto-imagen existentes con paráfrasis usando un gran modelo de lenguaje, y SelfEQ, una estrategia débilmente supervisada sobre mapas de explicación visual para paráfrasis que fomenta la autoconsistencia. En concreto, para una frase textual de entrada, intentamos generar una paráfrasis y ajustamos el modelo de modo que la frase y la paráfrasis se mapeen a la misma región en la imagen. Postulamos que esto a la vez amplía el vocabulario que el modelo es capaz de manejar y mejora la calidad de las ubicaciones de objetos resaltadas por los métodos de explicación visual basados en gradientes (p. ej., GradCAM). Demostramos que SelfEQ mejora el rendimiento en Flickr30k, ReferIt y RefCOCO+ sobre un método de referencia sólido y varios trabajos previos. En particular, en comparación con otros métodos que no usan ningún tipo de anotaciones de caja, obtenemos un 84,07% en Flickr30k (una mejora absoluta del 4,69%), un 67,40% en ReferIt (una mejora absoluta del 7,68%), y un 75,10% y un 55,49% en los conjuntos de prueba A y B de RefCOCO+ respectivamente (una mejora absoluta del 3,74% en promedio).
detalles
cita
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué problema aborda SelfEQ? SelfEQ mejora el grounding visual haciendo que un modelo de visión-lenguaje localice frases equivalentes, como "frisbee" y "disco", en la misma región de la imagen.
- ¿Cómo funciona el método sin supervisión por cajas delimitadoras? Usa mapas de explicación GradCAM de un modelo de visión-lenguaje existente como supervisión débil, y luego entrena el modelo de modo que una frase original y su paráfrasis produzcan mapas de localización consistentes.
- ¿Por qué son útiles aquí las paráfrasis generadas por un LLM? Las paráfrasis amplían la formulación que el modelo puede manejar y crean pares de equivalencia que enseñan al modelo a fundamentar de forma consistente descripciones semánticamente similares.
- ¿Cuál es el papel del objetivo SelfEQ? El objetivo combina la similitud de mapas de calor con un término de consistencia de la región de interés, de modo que los prompts parafraseados se alinean espacialmente evitando al mismo tiempo mapas de explicación uniformes triviales.
- ¿Qué benchmarks muestran el impacto del método? El artículo reporta mejoras en Flickr30k, ReferIt y RefCOCO+, incluyendo resultados sólidos entre los métodos que no usan anotaciones de caja.
Contribuciones principales
- El artículo introduce Self-consistency EQuivalence Tuning, un objetivo débilmente supervisado para mejorar el grounding visual mediante explicaciones consistentes a través de texto parafraseado.
- Muestra que las paráfrasis generadas por un LLM pueden usarse como señales de entrenamiento escalables para el grounding visual, convirtiendo la equivalencia lingüística en una supervisión espacial útil.
- El método mejora una canalización de grounding basada en ALBEF sin requerir cajas delimitadoras, máscaras de segmentación, detectores de objetos ni redes de propuesta de cajas.
- SelfEQ logra ganancias sustanciales sobre sólidas líneas de base débilmente supervisadas, incluyendo un 84,07% en Flickr30k, un 67,40% en ReferIt y una precisión mejorada en el juego de señalamiento de RefCOCO+.
- Las ablaciones clarifican por qué importa el ajuste explícito de equivalencia: simplemente añadir paráfrasis como pares imagen-texto adicionales es menos eficaz que imponer directamente explicaciones visuales autoconsistentes.
Limitaciones y advertencias
- SelfEQ está diseñado para el grounding débilmente supervisado con mapas de explicación, por lo que complementa en lugar de reemplazar a los sistemas de grounding totalmente supervisados cuando se dispone de cajas de alta calidad.
- El método depende de la calidad de las paráfrasis generadas, pero el artículo usa una estrategia clara de prompting y filtrado y muestra que los pares de equivalencia resultantes proporcionan ganancias prácticas.
- Dado que se construye sobre explicaciones de estilo GradCAM de un modelo base de visión-lenguaje, el rendimiento puede reflejar las fortalezas del modelo subyacente; esto hace que SelfEQ sea especialmente valioso como estrategia de ajuste para mejorar modelos existentes.
- La evaluación se centra en benchmarks estándar de grounding y en la precisión del juego de señalamiento, dejando la búsqueda visual del mundo real más amplia, la robótica y los entornos de accesibilidad como aplicaciones naturales a continuación.
- El enfoque se centra en el grounding de frases y regiones más que en el razonamiento visual abierto completo, lo que mantiene la contribución bien delimitada y hace que las ganancias reportadas sean más fáciles de interpretar.
Cómo interpretar este resultado
Este artículo se lee mejor como una sólida contribución al grounding visual débilmente supervisado: SelfEQ convierte la consistencia de las paráfrasis en una señal de entrenamiento práctica, mejorando la precisión de localización y la robustez de vocabulario sin necesitar costosas anotaciones de ubicación de objetos.