Improved Visual Grounding through Self-Consistent Explanations
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu tại Rice University và UC Irvine đã phát triển một kỹ thuật giúp các hệ thống AI xác định vị trí của các đối tượng trong ảnh một cách đáng tin cậy hơn khi được cung cấp một mô tả văn bản — một tác vụ gọi là định vị thị giác (visual grounding). Vấn đề cốt lõi mà họ giải quyết là các mô hình thị giác-ngôn ngữ hiện có, vốn học cách khớp ảnh với văn bản, có thể định vị chính xác một đối tượng như "frisbee" nhưng lại thất bại khi cùng đối tượng đó được mô tả bằng một từ khác, như "disc" (đĩa). Để khắc phục điều này, nhóm nghiên cứu tạo ra một cách tiếp cận huấn luyện gọi là SelfEQ (Self-consistency EQuivalence Tuning), sử dụng một mô hình ngôn ngữ lớn để tự động sinh ra các câu diễn giải lại cho chú thích ảnh và sau đó tinh chỉnh mô hình thị giác sao cho cả cụm từ gốc lẫn câu diễn giải lại của nó đều tạo ra cùng một vùng được làm nổi bật trong ảnh. Phương pháp hoạt động mà không cần bất kỳ chú thích hộp giới hạn (bounding box) nào, thay vào đó dựa vào các bản đồ giải thích thị giác dựa trên gradient — cụ thể là GradCAM — như một dạng giám sát yếu. Được kiểm thử trên ba benchmark tiêu chuẩn, SelfEQ cải thiện độ chính xác định vị thêm 4.69 điểm phần trăm trên Flickr30k, 7.68 điểm trên ReferIt, và trung bình 3.74 điểm trên RefCOCO+, vượt qua hầu hết các phương pháp khác cũng bỏ qua giám sát hộp giới hạn và thậm chí sánh ngang một số phương pháp có sử dụng nó. Kết quả thực tiễn là một mô hình xử lý được vốn từ vựng rộng hơn và định vị các đối tượng nhất quán hơn — một tiến bộ hữu ích cho các ứng dụng như tìm kiếm thị giác và tương tác người-máy vốn phụ thuộc vào việc kết nối ngôn ngữ với những phần cụ thể của một ảnh.
tóm tắt
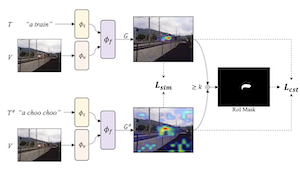
Các mô hình thị giác-ngôn ngữ (VL) được huấn luyện để khớp ảnh với văn bản có thể được kết hợp với các phương pháp giải thích thị giác để chỉ ra vị trí của những đối tượng cụ thể trong một ảnh. Công trình của chúng tôi cho thấy khả năng định vị --"grounding"-- của các mô hình này có thể được cải thiện thêm bằng cách tinh chỉnh cho các giải thích thị giác tự nhất quán. Chúng tôi đề xuất một chiến lược bổ sung dữ liệu cho các tập dữ liệu văn bản-ảnh hiện có bằng các câu diễn giải lại (paraphrase) sử dụng một mô hình ngôn ngữ lớn, và SelfEQ, một chiến lược giám sát yếu trên các bản đồ giải thích thị giác cho các câu diễn giải lại nhằm khuyến khích tính tự nhất quán. Cụ thể, với một cụm từ văn bản đầu vào, chúng tôi cố gắng sinh ra một câu diễn giải lại và tinh chỉnh mô hình sao cho cụm từ và câu diễn giải lại ánh xạ tới cùng một vùng trong ảnh. Chúng tôi cho rằng điều này vừa mở rộng vốn từ vựng mà mô hình có thể xử lý, vừa cải thiện chất lượng của các vị trí đối tượng được làm nổi bật bởi các phương pháp giải thích thị giác dựa trên gradient (ví dụ GradCAM). Chúng tôi chứng minh rằng SelfEQ cải thiện hiệu năng trên Flickr30k, ReferIt, và RefCOCO+ so với một phương pháp baseline mạnh và một số công trình trước đó. Đặc biệt, so với các phương pháp khác không sử dụng bất kỳ loại chú thích hộp (box) nào, chúng tôi đạt 84.07% trên Flickr30k (cải thiện tuyệt đối 4.69%), 67.40% trên ReferIt (cải thiện tuyệt đối 7.68%), và lần lượt 75.10%, 55.49% trên các tập kiểm thử A và B của RefCOCO+ (cải thiện tuyệt đối trung bình 3.74%).
chi tiết
trích dẫn
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- SelfEQ giải quyết vấn đề nào? SelfEQ cải thiện định vị thị giác bằng cách làm cho một mô hình thị giác-ngôn ngữ định vị các cụm từ tương đương, chẳng hạn "frisbee" và "disc", về cùng một vùng ảnh.
- Phương pháp hoạt động như thế nào mà không cần giám sát hộp giới hạn? Nó sử dụng các bản đồ giải thích GradCAM từ một mô hình thị giác-ngôn ngữ hiện có làm giám sát yếu, rồi huấn luyện mô hình sao cho một cụm từ gốc và câu diễn giải lại của nó tạo ra các bản đồ định vị nhất quán.
- Tại sao các câu diễn giải lại do LLM sinh ra lại hữu ích ở đây? Các câu diễn giải lại mở rộng cách diễn đạt mà mô hình có thể xử lý và tạo ra các cặp tương đương dạy mô hình định vị nhất quán những mô tả tương tự về mặt ngữ nghĩa.
- Vai trò của mục tiêu SelfEQ là gì? Mục tiêu này kết hợp độ tương đồng của heatmap với một thành phần nhất quán vùng quan tâm (region-of-interest) sao cho các prompt được diễn giải lại căn chỉnh về mặt không gian trong khi tránh các bản đồ giải thích đồng đều tầm thường.
- Những benchmark nào cho thấy tác động của phương pháp? Bài báo báo cáo các cải thiện trên Flickr30k, ReferIt, và RefCOCO+, bao gồm các kết quả mạnh trong số các phương pháp không sử dụng chú thích hộp.
Đóng góp chính
- Bài báo giới thiệu Self-consistency EQuivalence Tuning, một mục tiêu giám sát yếu để cải thiện định vị thị giác thông qua các giải thích nhất quán giữa các văn bản được diễn giải lại.
- Bài báo cho thấy các câu diễn giải lại do LLM sinh ra có thể được dùng làm tín hiệu huấn luyện có khả năng mở rộng cho định vị thị giác, biến sự tương đương ngôn ngữ thành giám sát không gian hữu ích.
- Phương pháp cải thiện một quy trình định vị dựa trên ALBEF mà không cần hộp giới hạn, mặt nạ phân vùng, bộ phát hiện đối tượng, hay mạng đề xuất hộp.
- SelfEQ đạt được những cải thiện đáng kể so với các baseline giám sát yếu mạnh, bao gồm 84.07% trên Flickr30k, 67.40% trên ReferIt, và độ chính xác pointing-game được cải thiện trên RefCOCO+.
- Các phân tích loại bỏ làm rõ tại sao việc tinh chỉnh tương đương rõ ràng lại quan trọng: việc chỉ đơn giản thêm các câu diễn giải lại làm các cặp ảnh-văn bản bổ sung kém hiệu quả hơn so với việc trực tiếp thực thi các giải thích thị giác tự nhất quán.
Hạn chế và lưu ý
- SelfEQ được thiết kế cho định vị giám sát yếu với các bản đồ giải thích, nên nó bổ trợ chứ không thay thế các hệ thống định vị giám sát đầy đủ khi có sẵn các hộp chất lượng cao.
- Phương pháp phụ thuộc vào chất lượng của các câu diễn giải lại được sinh ra, nhưng bài báo sử dụng một chiến lược prompting và lọc rõ ràng và cho thấy các cặp tương đương thu được mang lại những cải thiện thực tiễn.
- Vì xây dựng trên các giải thích kiểu GradCAM từ một mô hình thị giác-ngôn ngữ cơ sở, hiệu năng có thể phản ánh điểm mạnh của mô hình nền tảng; điều này khiến SelfEQ đặc biệt giá trị như một chiến lược tinh chỉnh để cải thiện các mô hình hiện có.
- Đánh giá tập trung vào các benchmark định vị tiêu chuẩn và độ chính xác pointing-game, để lại các bối cảnh thực tế rộng hơn như tìm kiếm thị giác, robotics, và khả năng tiếp cận làm những ứng dụng tiếp theo tự nhiên.
- Cách tiếp cận tập trung vào định vị cụm từ và vùng thay vì suy luận thị giác mở hoàn toàn, điều giữ cho đóng góp được nhắm trúng đích và làm cho các cải thiện được báo cáo dễ diễn giải hơn.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một đóng góp mạnh cho định vị thị giác giám sát yếu: SelfEQ biến tính nhất quán của câu diễn giải lại thành một tín hiệu huấn luyện thực tiễn, cải thiện độ chính xác định vị và độ bền vững của vốn từ vựng mà không cần các chú thích vị trí đối tượng đắt đỏ.