Improved Visual Grounding through Self-Consistent Explanations
Sintesi del comunicato stampa
I ricercatori della Rice University e della UC Irvine hanno sviluppato una tecnica per aiutare i sistemi di IA a individuare in modo più affidabile la posizione degli oggetti nelle immagini quando viene fornita una descrizione testuale — un compito noto come visual grounding. Il problema centrale che hanno affrontato è che i modelli vision-language esistenti, che imparano ad abbinare immagini e testo, riescono a localizzare correttamente un oggetto come un "frisbee" ma falliscono quando lo stesso oggetto viene descritto con una parola diversa, come "disco". Per risolvere questo, il team ha creato un approccio di addestramento chiamato SelfEQ (Self-consistency EQuivalence Tuning), che utilizza un grande modello linguistico per generare automaticamente parafrasi delle didascalie delle immagini e poi effettua il finetuning del modello visivo in modo che sia la frase originale sia la sua parafrasi producano la stessa regione evidenziata nell'immagine. Il metodo funziona senza richiedere alcuna annotazione con bounding box, affidandosi invece a mappe di spiegazione visiva basate sul gradiente — nello specifico GradCAM — come forma di supervisione debole. Testato su tre benchmark standard, SelfEQ ha migliorato l'accuratezza di localizzazione di 4.69 punti percentuali su Flickr30k, 7.68 punti su ReferIt e una media di 3.74 punti su RefCOCO+, battendo la maggior parte degli altri metodi che a loro volta evitano la supervisione con bounding box e rivaleggiando persino con alcuni che la utilizzano. Il risultato pratico è un modello che gestisce un vocabolario più ampio e localizza gli oggetti in modo più coerente — un progresso utile per applicazioni come la ricerca visiva e l'interazione uomo-macchina che dipendono dal collegare il linguaggio a parti specifiche di un'immagine.
abstract
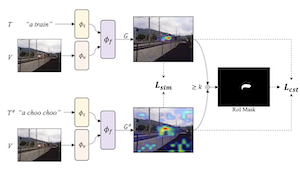
I modelli vision-and-language addestrati ad abbinare immagini e testo possono essere combinati con metodi di spiegazione visiva per indicare la posizione di oggetti specifici in un'immagine. Il nostro lavoro mostra che le capacità di localizzazione — il "grounding" — di questi modelli possono essere ulteriormente migliorate tramite finetuning per ottenere spiegazioni visive auto-coerenti. Proponiamo una strategia per arricchire i dataset testo-immagine esistenti con parafrasi utilizzando un grande modello linguistico, e SelfEQ, una strategia debolmente supervisionata sulle mappe di spiegazione visiva per le parafrasi che incoraggia l'auto-coerenza. Nello specifico, per una frase testuale di input, tentiamo di generare una parafrasi e di effettuare il finetuning del modello in modo che la frase e la parafrasi vengano mappate sulla stessa regione dell'immagine. Ipotizziamo che questo, da un lato, ampli il vocabolario che il modello è in grado di gestire e, dall'altro, migliori la qualità delle posizioni degli oggetti evidenziate dai metodi di spiegazione visiva basati sul gradiente (ad es. GradCAM). Dimostriamo che SelfEQ migliora le prestazioni su Flickr30k, ReferIt e RefCOCO+ rispetto a un solido metodo di riferimento e a diversi lavori precedenti. In particolare, rispetto ad altri metodi che non utilizzano alcun tipo di annotazione con bounding box, otteniamo l'84.07% su Flickr30k (un miglioramento assoluto del 4.69%), il 67.40% su ReferIt (un miglioramento assoluto del 7.68%) e il 75.10% e 55.49% rispettivamente sui test set A e B di RefCOCO+ (un miglioramento assoluto del 3.74% in media).
dettagli
citazione
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Quale problema affronta SelfEQ? SelfEQ migliora il visual grounding facendo in modo che un modello vision-language localizzi frasi equivalenti, come "frisbee" e "disco", sulla stessa regione dell'immagine.
- Come funziona il metodo senza supervisione con bounding box? Utilizza le mappe di spiegazione GradCAM di un modello vision-language esistente come supervisione debole, quindi addestra il modello in modo che una frase originale e la sua parafrasi producano mappe di localizzazione coerenti.
- Perché le parafrasi generate dagli LLM sono utili in questo contesto? Le parafrasi ampliano il lessico che il modello può gestire e creano coppie di equivalenza che insegnano al modello a effettuare in modo coerente il grounding di descrizioni semanticamente simili.
- Qual è il ruolo dell'obiettivo SelfEQ? L'obiettivo combina la somiglianza tra heatmap con un termine di coerenza sulla regione di interesse in modo che i prompt parafrasati si allineino spazialmente evitando al contempo mappe di spiegazione uniformi e banali.
- Quali benchmark mostrano l'impatto del metodo? Il paper riporta miglioramenti su Flickr30k, ReferIt e RefCOCO+, inclusi forti risultati tra i metodi che non utilizzano annotazioni con bounding box.
Principali contributi
- Il paper introduce il Self-consistency EQuivalence Tuning, un obiettivo debolmente supervisionato per migliorare il visual grounding attraverso spiegazioni coerenti tra testi parafrasati.
- Mostra che le parafrasi generate dagli LLM possono essere usate come segnali di addestramento scalabili per il visual grounding, trasformando l'equivalenza linguistica in una utile supervisione spaziale.
- Il metodo migliora una pipeline di grounding basata su ALBEF senza richiedere bounding box, maschere di segmentazione, object detector o reti di proposta di box.
- SelfEQ ottiene guadagni sostanziali rispetto a solide baseline debolmente supervisionate, inclusi l'84.07% su Flickr30k, il 67.40% su ReferIt e una migliore accuratezza nel pointing-game su RefCOCO+.
- Le ablation chiariscono perché il tuning esplicito di equivalenza è importante: aggiungere semplicemente le parafrasi come ulteriori coppie immagine-testo è meno efficace che imporre direttamente spiegazioni visive auto-coerenti.
Limiti e avvertenze
- SelfEQ è progettato per il grounding debolmente supervisionato con mappe di spiegazione, quindi complementa anziché sostituire i sistemi di grounding pienamente supervisionati quando sono disponibili box di alta qualità.
- Il metodo dipende dalla qualità delle parafrasi generate, ma il paper utilizza una chiara strategia di prompting e filtraggio e mostra che le coppie di equivalenza risultanti forniscono guadagni pratici.
- Poiché si basa su spiegazioni in stile GradCAM provenienti da un modello vision-language di base, le prestazioni possono riflettere i punti di forza del modello sottostante; ciò rende SelfEQ particolarmente prezioso come strategia di tuning per migliorare i modelli esistenti.
- La valutazione si concentra su benchmark di grounding standard e sull'accuratezza nel pointing-game, lasciando i contesti più ampi del mondo reale di ricerca visiva, robotica e accessibilità come naturali applicazioni successive.
- L'approccio si concentra sul grounding di frasi e regioni anziché sul ragionamento visivo open-ended completo, il che mantiene il contributo ben mirato e rende i guadagni riportati più facili da interpretare.
Come interpretare questo risultato
Questo paper si legge al meglio come un solido contributo al visual grounding debolmente supervisionato: SelfEQ trasforma la coerenza delle parafrasi in un segnale di addestramento pratico, migliorando l'accuratezza di localizzazione e la robustezza del vocabolario senza necessità di costose annotazioni della posizione degli oggetti.