Improved Visual Grounding through Self-Consistent Explanations
보도 자료 요약
라이스 대학교와 UC Irvine의 연구진은 텍스트 설명이 주어졌을 때 AI 시스템이 이미지 내 객체의 위치를 더 신뢰성 있게 정확히 짚어내도록 돕는 기법을 개발했는데, 이는 시각적 그라운딩(visual grounding)으로 알려진 작업이다. 연구진이 다룬 핵심 문제는, 이미지와 텍스트를 매칭하도록 학습하는 기존 비전-언어 모델이 "frisbee"와 같은 객체는 올바르게 찾아내지만 동일한 객체가 "disc"와 같이 다른 단어로 설명되면 실패한다는 점이다. 이를 해결하기 위해 연구팀은 대규모 언어 모델을 사용하여 이미지 캡션에 대한 패러프레이즈를 자동으로 생성한 다음, 원래 구문과 그 패러프레이즈가 이미지에서 동일하게 강조된 영역을 만들어내도록 시각 모델을 미세조정하는 SelfEQ(Self-consistency EQuivalence Tuning)라는 학습 접근법을 만들었다. 이 방법은 어떠한 바운딩 박스 주석도 요구하지 않고, 대신 약지도(weak supervision)의 한 형태로 기울기 기반 시각 설명 지도, 구체적으로 GradCAM에 의존한다. 세 가지 표준 벤치마크에서 테스트한 결과, SelfEQ는 Flickr30k에서 위치 파악 정확도를 4.69%포인트, ReferIt에서 7.68%포인트, RefCOCO+에서 평균 3.74%포인트 향상시켜, 바운딩 박스 지도를 마찬가지로 생략하는 다른 대부분의 방법을 능가하고 심지어 박스를 사용하는 일부 방법에 필적했다. 실용적 결과는 더 넓은 어휘를 다루고 객체를 더 일관되게 위치 파악하는 모델로, 언어를 이미지의 특정 부분과 연결하는 데 의존하는 시각 검색이나 인간-기계 상호작용 같은 응용에 유용한 진전이다.
초록
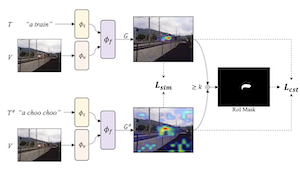
이미지와 텍스트를 매칭하도록 학습된 비전-언어 모델은 시각적 설명 방법과 결합되어 이미지 내 특정 객체의 위치를 가리킬 수 있다. 우리의 연구는 이러한 모델의 위치 파악(localization), 즉 "그라운딩(grounding)" 능력이 자기 일관적 시각 설명을 위한 미세조정을 통해 더욱 향상될 수 있음을 보인다. 우리는 대규모 언어 모델을 사용하여 기존 텍스트-이미지 데이터셋을 패러프레이즈로 증강하는 전략과, 패러프레이즈에 대한 시각 설명 지도(map)에서 자기 일관성을 장려하는 약지도 전략인 SelfEQ를 제안한다. 구체적으로, 입력 텍스트 구문에 대해 우리는 패러프레이즈를 생성하고 그 구문과 패러프레이즈가 이미지의 동일한 영역에 매핑되도록 모델을 미세조정한다. 우리는 이것이 모델이 다룰 수 있는 어휘를 확장하는 동시에 기울기 기반 시각 설명 방법(예: GradCAM)이 강조하는 객체 위치의 품질을 향상시킨다고 본다. 우리는 SelfEQ가 강력한 기준 방법과 여러 선행 연구를 능가하여 Flickr30k, ReferIt, RefCOCO+에서 성능을 향상시킴을 입증한다. 특히 어떠한 종류의 박스 주석도 사용하지 않는 다른 방법들과 비교하여, Flickr30k에서 84.07%(절대 4.69% 향상), ReferIt에서 67.40%(절대 7.68% 향상), RefCOCO+ 테스트 셋 A와 B에서 각각 75.10%, 55.49%(평균 절대 3.74% 향상)를 달성한다.
세부 정보
인용
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- SelfEQ는 어떤 문제를 다루는가? SelfEQ는 비전-언어 모델이 "frisbee"와 "disc"처럼 동등한 구문을 동일한 이미지 영역에 위치 파악하도록 만들어 시각적 그라운딩을 향상시킨다.
- 이 방법은 바운딩 박스 지도 없이 어떻게 작동하는가? 기존 비전-언어 모델의 GradCAM 설명 지도를 약지도로 사용한 다음, 원래 구문과 그 패러프레이즈가 일관된 위치 파악 지도를 생성하도록 모델을 학습시킨다.
- 여기서 LLM이 생성한 패러프레이즈가 유용한 이유는 무엇인가? 패러프레이즈는 모델이 다룰 수 있는 표현을 확장하고, 의미적으로 유사한 설명을 일관되게 그라운딩하도록 모델을 가르치는 동등성 쌍을 만든다.
- SelfEQ 목적함수의 역할은 무엇인가? 이 목적함수는 히트맵 유사도와 관심 영역(region-of-interest) 일관성 항을 결합하여, 패러프레이즈된 프롬프트가 공간적으로 정렬되면서도 사소한 균일한 설명 지도를 피하도록 한다.
- 어떤 벤치마크가 이 방법의 효과를 보여주는가? 논문은 Flickr30k, ReferIt, RefCOCO+에서의 향상을 보고하며, 박스 주석을 사용하지 않는 방법들 가운데 강력한 결과를 포함한다.
주요 기여
- 이 논문은 패러프레이즈된 텍스트 전반에 걸친 일관된 설명을 통해 시각적 그라운딩을 향상시키는 약지도 목적함수인 Self-consistency EQuivalence Tuning을 소개한다.
- LLM이 생성한 패러프레이즈가 시각적 그라운딩을 위한 확장 가능한 학습 신호로 사용될 수 있어, 언어적 동등성을 유용한 공간적 지도로 전환함을 보인다.
- 이 방법은 바운딩 박스, 분할 마스크, 객체 검출기, 박스 제안 네트워크를 요구하지 않고 ALBEF 기반 그라운딩 파이프라인을 향상시킨다.
- SelfEQ는 Flickr30k에서 84.07%, ReferIt에서 67.40%, 향상된 RefCOCO+ 포인팅 게임(pointing-game) 정확도를 포함하여 강력한 약지도 기준선 대비 상당한 향상을 달성한다.
- 제거(ablation) 실험은 명시적인 동등성 튜닝이 왜 중요한지를 명확히 한다: 단순히 패러프레이즈를 추가적인 이미지-텍스트 쌍으로 더하는 것은 자기 일관적 시각 설명을 직접 강제하는 것보다 덜 효과적이다.
한계 및 유의 사항
- SelfEQ는 설명 지도를 활용한 약지도 그라운딩을 위해 설계되었으므로, 고품질 박스를 사용할 수 있을 때 완전 지도 그라운딩 시스템을 대체하기보다는 보완한다.
- 이 방법은 생성된 패러프레이즈의 품질에 의존하지만, 논문은 명확한 프롬프팅 및 필터링 전략을 사용하며 그 결과로 얻어진 동등성 쌍이 실용적인 향상을 제공함을 보인다.
- 기반 비전-언어 모델의 GradCAM 방식 설명 위에 구축되기 때문에 성능은 기저 모델의 강점을 반영할 수 있는데, 이는 SelfEQ를 기존 모델 향상을 위한 튜닝 전략으로서 특히 가치 있게 만든다.
- 평가는 표준 그라운딩 벤치마크와 포인팅 게임 정확도에 집중되어 있어, 더 광범위한 실세계 시각 검색, 로보틱스, 접근성 환경은 자연스러운 다음 응용으로 남는다.
- 이 접근법은 완전한 개방형 시각 추론보다는 구문 및 영역 그라운딩에 초점을 맞추는데, 이는 기여를 잘 겨냥된 상태로 유지하고 보고된 향상을 더 쉽게 해석할 수 있게 한다.
이 결과를 읽는 방법
이 논문은 약지도 시각적 그라운딩에 대한 강력한 기여로 읽는 것이 가장 좋다: SelfEQ는 패러프레이즈 일관성을 실용적인 학습 신호로 전환하여, 비용이 큰 객체 위치 주석을 요구하지 않고도 위치 파악 정확도와 어휘 견고성을 향상시킨다.