Estimating and Maximizing Mutual Information for Knowledge Distillation
Resumen de prensa
Investigadores de la Universidad de Virginia y la Universidad Rice han desarrollado una nueva técnica para reducir grandes modelos de inteligencia artificial a tamaños que pueden ejecutarse en teléfonos y otros dispositivos con recursos limitados, sin sacrificar demasiada precisión. El desafío central en este campo, conocido como destilación de conocimiento, consiste en lograr que una red neuronal "estudiante" más pequeña absorba información útil de una red "maestra" más grande y capaz. Los métodos existentes suelen hacer esto emparejando las salidas o las representaciones intermedias de ambas redes mediante métricas de distancia simples, que pueden tener dificultades cuando el maestro y el estudiante tienen arquitecturas internas muy diferentes. El nuevo marco, llamado MIMKD (Destilación de Conocimiento por Maximización de la Información Mutua), adopta un enfoque distinto al usar un objetivo de aprendizaje contrastivo arraigado en la teoría de la información —específicamente, un estimador basado en la divergencia de Jensen-Shannon— para estimar y maximizar de manera simultánea la información mutua compartida entre las representaciones de ambas redes, tanto a nivel de las características globales finales como a niveles más detallados de características locales e intermedias. Una ventaja práctica es que esta formulación, a diferencia de métodos competidores como la Destilación de Representación Contrastiva, solo requiere una única muestra negativa durante el entrenamiento en lugar de miles, lo que la hace mucho menos intensiva en memoria y más aplicable a las capas intermedias de la red. En pruebas sobre los benchmarks de clasificación de imágenes CIFAR-100 e ImageNet, MIMKD superó de manera consistente a las alternativas establecidas en una amplia gama de emparejamientos maestro-estudiante, incluidos casos en los que las dos redes tenían diseños muy diferentes, elevando la precisión de una ShuffleNetV2 en casi 5 puntos porcentuales usando un maestro ResNet-50 y mejorando una ResNet-18 en ImageNet en 1.44 puntos porcentuales respecto a su línea base, resultados que sugieren que el enfoque podría ayudar a que modelos de IA capaces sean más prácticos de desplegar en el borde.
resumen
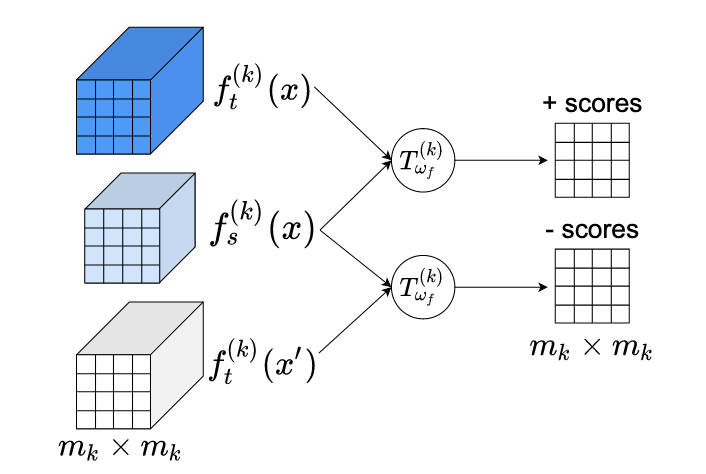
En este trabajo, proponemos la Destilación de Conocimiento por Maximización de la Información Mutua (MIMKD). Nuestro método utiliza un objetivo contrastivo para estimar y maximizar de manera simultánea una cota inferior de la información mutua de las representaciones de características locales y globales entre una red maestra y una red estudiante. Demostramos mediante experimentos extensos que esto puede usarse para mejorar el rendimiento de modelos de baja capacidad transfiriendo conocimiento desde modelos más eficaces pero computacionalmente costosos. Esto puede utilizarse para producir mejores modelos que pueden ejecutarse en dispositivos con bajos recursos computacionales. Nuestro método es flexible: podemos destilar conocimiento desde maestros con arquitecturas de red arbitrarias hacia redes estudiantes arbitrarias. Nuestros resultados empíricos muestran que MIMKD supera a los enfoques competidores en una amplia gama de pares estudiante-maestro con diferentes capacidades, con diferentes arquitecturas, y cuando las redes estudiantes tienen una capacidad extremadamente baja. Logramos obtener una precisión del 74.55% en CIFAR100 con una ShufflenetV2 a partir de una precisión base del 69.8% destilando conocimiento desde una ResNet-50. En Imagenet mejoramos una red ResNet-18 del 68.88% al 70.32% de precisión (1.44%+) usando una red maestra ResNet-34.
cita
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}