Estimating and Maximizing Mutual Information for Knowledge Distillation
Résumé du communiqué de presse
Des chercheurs de l'University of Virginia et de Rice University ont mis au point une nouvelle technique pour réduire de grands modèles d'intelligence artificielle à des tailles pouvant fonctionner sur des téléphones et d'autres appareils aux ressources limitées, sans trop sacrifier leur précision. Le défi central de ce domaine, connu sous le nom de distillation de connaissances, consiste à amener un réseau de neurones « étudiant » plus petit à absorber des informations utiles d'un réseau « enseignant » plus grand et plus performant. Les méthodes existantes y parviennent généralement en faisant correspondre les sorties ou les représentations intermédiaires des deux réseaux à l'aide de simples métriques de distance, ce qui peut s'avérer difficile lorsque l'enseignant et l'étudiant ont des architectures internes très différentes. Le nouveau cadre, appelé MIMKD (Mutual Information Maximization Knowledge Distillation), adopte une approche différente en utilisant un objectif d'apprentissage contrastif enraciné dans la théorie de l'information — plus précisément un estimateur fondé sur la divergence de Jensen-Shannon — pour estimer et maximiser simultanément l'information mutuelle partagée entre les représentations des deux réseaux, à la fois au niveau des caractéristiques globales finales et à des niveaux de caractéristiques locales et intermédiaires plus fins. Un avantage pratique est que cette formulation, contrairement à des méthodes concurrentes telles que la Contrastive Representation Distillation, ne nécessite qu'un seul échantillon négatif durant l'entraînement plutôt que des milliers, ce qui la rend bien moins gourmande en mémoire et plus applicable aux couches intermédiaires du réseau. Lors de tests sur les bancs d'essai de classification d'images CIFAR-100 et ImageNet, MIMKD a systématiquement surpassé les alternatives établies sur un large éventail d'appariements enseignant-étudiant, y compris dans des cas où les deux réseaux avaient des conceptions très différentes, augmentant la précision d'un ShuffleNetV2 de près de 5 points de pourcentage à l'aide d'un enseignant ResNet-50 et améliorant un ResNet-18 sur ImageNet de 1,44 point de pourcentage par rapport à sa référence — des résultats qui suggèrent que l'approche pourrait contribuer à rendre des modèles d'IA performants plus pratiques à déployer en périphérie.
résumé
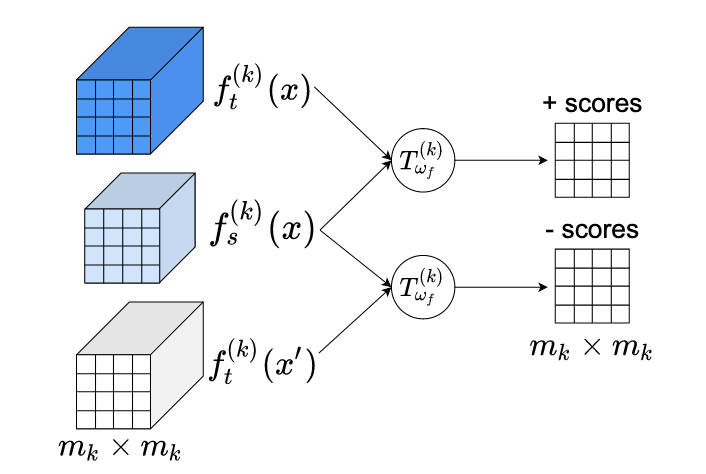
Dans ce travail, nous proposons la distillation de connaissances par maximisation de l'information mutuelle (Mutual Information Maximization Knowledge Distillation, MIMKD). Notre méthode utilise un objectif contrastif pour estimer et maximiser simultanément une borne inférieure sur l'information mutuelle des représentations de caractéristiques locales et globales entre un réseau enseignant et un réseau étudiant. Nous démontrons au moyen d'expériences approfondies que cela peut servir à améliorer les performances de modèles à faible capacité en transférant des connaissances depuis des modèles plus performants mais coûteux en calcul. Cela peut être utilisé pour produire de meilleurs modèles pouvant être exécutés sur des appareils disposant de faibles ressources de calcul. Notre méthode est flexible : nous pouvons distiller des connaissances depuis des enseignants aux architectures de réseau arbitraires vers des étudiants arbitraires. Nos résultats empiriques montrent que MIMKD surpasse les approches concurrentes sur un large éventail de paires étudiant-enseignant de capacités différentes, d'architectures différentes, et lorsque les réseaux étudiants sont de capacité extrêmement faible. Nous parvenons à obtenir une précision de 74,55% sur CIFAR100 avec un ShufflenetV2, à partir d'une précision de référence de 69,8%, en distillant les connaissances d'un ResNet-50. Sur Imagenet, nous améliorons un réseau ResNet-18 de 68,88% à 70,32% de précision (+1,44%) à l'aide d'un réseau enseignant ResNet-34.
citation
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}