Estimating and Maximizing Mutual Information for Knowledge Distillation
Resumo do comunicado de imprensa
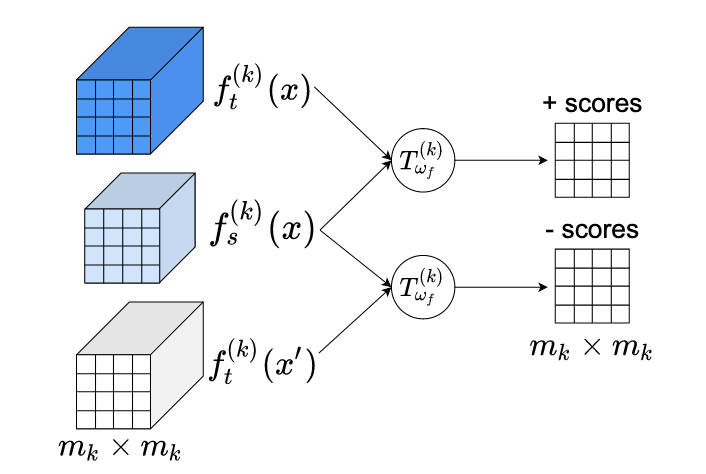
Pesquisadores da University of Virginia e da Rice University desenvolveram uma nova técnica para reduzir grandes modelos de inteligência artificial a tamanhos que podem ser executados em telefones e outros dispositivos com recursos limitados, sem sacrificar muito de sua acurácia. O desafio central nesse campo, conhecido como destilação de conhecimento, é fazer com que uma rede neural "estudante" menor absorva informações úteis de uma rede "professora" maior e mais capaz. Os métodos existentes normalmente fazem isso combinando as saídas ou as representações intermediárias das duas redes usando métricas de distância simples, que podem ter dificuldade quando o professor e o estudante têm arquiteturas internas muito diferentes. O novo framework, chamado MIMKD (Mutual Information Maximization Knowledge Distillation), adota uma abordagem diferente ao usar um objetivo de aprendizado contrastivo enraizado na teoria da informação — especificamente, um estimador baseado na divergência de Jensen-Shannon — para simultaneamente estimar e maximizar a informação mútua compartilhada entre as representações das duas redes, tanto no nível das características globais finais quanto em níveis de características locais e intermediárias de granularidade mais fina. Uma vantagem prática é que essa formulação, diferentemente de métodos concorrentes como a Contrastive Representation Distillation, requer apenas uma única amostra negativa durante o treinamento, em vez de milhares, tornando-a muito menos intensiva em memória e mais aplicável a camadas intermediárias da rede. Em testes nos benchmarks de classificação de imagens CIFAR-100 e ImageNet, a MIMKD superou consistentemente alternativas estabelecidas em uma ampla gama de pareamentos professor-estudante, incluindo casos em que as duas redes tinham designs muito diferentes, elevando a acurácia de um ShuffleNetV2 em quase 5 pontos percentuais usando um professor ResNet-50 e melhorando um ResNet-18 no ImageNet em 1,44 ponto percentual em relação à sua referência — resultados que sugerem que a abordagem poderia ajudar a tornar modelos de IA capazes mais práticos para implantação na borda.
resumo
Neste trabalho, propomos a Mutual Information Maximization Knowledge Distillation (MIMKD). Nosso método usa um objetivo contrastivo para simultaneamente estimar e maximizar um limite inferior sobre a informação mútua das representações de características locais e globais entre uma rede professora e uma rede estudante. Demonstramos por meio de extensos experimentos que isso pode ser usado para melhorar o desempenho de modelos de baixa capacidade transferindo conhecimento de modelos mais eficazes, porém computacionalmente caros. Isso pode ser usado para produzir modelos melhores que podem ser executados em dispositivos com baixos recursos computacionais. Nosso método é flexível: podemos destilar conhecimento de professores com arquiteturas de rede arbitrárias para redes estudantes arbitrárias. Nossos resultados empíricos mostram que a MIMKD supera abordagens concorrentes em uma ampla gama de pares estudante-professor com diferentes capacidades, com diferentes arquiteturas e quando as redes estudantes têm capacidade extremamente baixa. Conseguimos obter 74,55% de acurácia no CIFAR100 com um ShufflenetV2 a partir de uma acurácia de referência de 69,8% destilando conhecimento de um ResNet-50. No Imagenet, melhoramos uma rede ResNet-18 de 68,88% para 70,32% de acurácia (+1,44%) usando uma rede professora ResNet-34.
citação
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}