Estimating and Maximizing Mutual Information for Knowledge Distillation
Краткое изложение пресс-релиза
Исследователи из University of Virginia и Rice University разработали новую технику сжатия больших моделей искусственного интеллекта до размеров, способных работать на телефонах и других устройствах с ограниченными ресурсами, без чрезмерной потери точности. Основная задача в этой области, известной как дистилляция знаний (knowledge distillation), — заставить меньшую "ученическую" нейронную сеть впитать полезную информацию из более крупной, более способной сети-"учителя". Существующие методы обычно делают это, сопоставляя выходы или промежуточные представления двух сетей с помощью простых метрик расстояния, что может давать сбои, когда учитель и ученик имеют очень разные внутренние архитектуры. Новый фреймворк под названием MIMKD (Mutual Information Maximization Knowledge Distillation) использует иной подход, применяя цель Contrastive Learning, укоренённую в теории информации — а именно оценщик на основе дивергенции Йенсена-Шеннона, — чтобы одновременно оценивать и максимизировать взаимную информацию, разделяемую представлениями двух сетей, как на уровне итоговых глобальных признаков, так и на более детальных локальных и промежуточных уровнях признаков. Практическое преимущество в том, что эта формулировка, в отличие от конкурирующих методов, таких как Contrastive Representation Distillation, требует во время обучения лишь одного негативного примера, а не тысяч, что делает её гораздо менее требовательной к памяти и более применимой к промежуточным слоям сети. В тестах на бенчмарках классификации изображений CIFAR-100 и ImageNet MIMKD стабильно превосходил устоявшиеся альтернативы на широком наборе пар учитель-ученик, включая случаи, когда две сети имели очень разные конструкции, повысив точность ShuffleNetV2 почти на 5 процентных пунктов с помощью учителя ResNet-50 и улучшив ResNet-18 на ImageNet на 1,44 процентного пункта относительно его базового уровня — результаты, наводящие на мысль, что подход может помочь сделать способные модели ИИ более практичными для развёртывания на периферии (edge).
аннотация
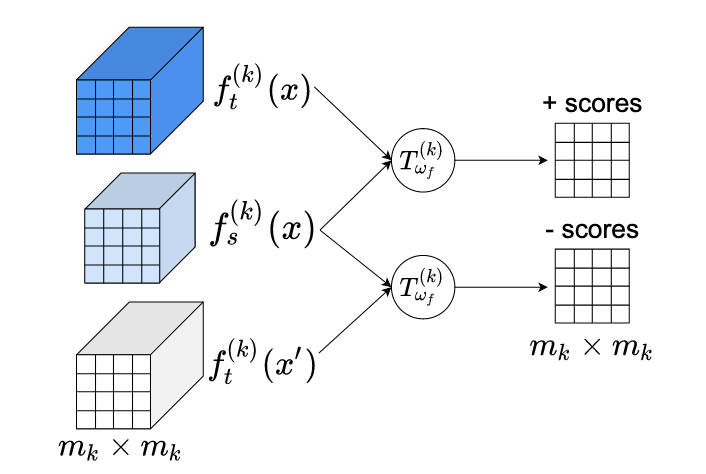
В этой работе мы предлагаем Mutual Information Maximization Knowledge Distillation (MIMKD). Наш метод использует контрастивную целевую функцию для одновременной оценки и максимизации нижней границы взаимной информации локальных и глобальных признаковых представлений между сетью-учителем и сетью-учеником. Посредством обширных экспериментов мы демонстрируем, что это можно использовать для повышения производительности маломощных моделей путём переноса знаний из более производительных, но вычислительно затратных моделей. Это можно использовать для создания более качественных моделей, способных работать на устройствах с низкими вычислительными ресурсами. Наш метод гибок: мы можем дистиллировать знания от учителей с произвольными сетевыми архитектурами в произвольные сети-ученики. Наши эмпирические результаты показывают, что MIMKD превосходит конкурирующие подходы на широком наборе пар ученик-учитель с разной ёмкостью, с разными архитектурами и когда сети-ученики имеют крайне малую ёмкость. Нам удаётся получить точность 74,55% на CIFAR100 с ShufflenetV2 при базовой точности 69,8%, дистиллируя знания из ResNet-50. На ImageNet мы улучшаем сеть ResNet-18 с 68,88% до 70,32% точности (+1,44%), используя сеть-учитель ResNet-34.
цитирование
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}