Text2Scene: Generating Compositional Scenes from Textual Descriptions
Resumen de prensa
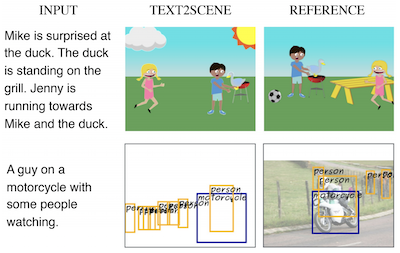
Investigadores de la Universidad de Virginia y del Thomas J. Watson Research Center de IBM han desarrollado un sistema llamado Text2Scene que puede generar automáticamente escenas visuales a partir de descripciones escritas, sin depender de las Redes Generativas Adversarias, o GANs, en las que se basan la mayoría de los enfoques competidores. En lugar de intentar sintetizar una imagen entera de una sola vez, el sistema funciona más como un ilustrador cuidadoso: lee una oración y luego coloca objetos uno a uno sobre un lienzo en blanco, decidiendo en cada paso qué añadir a continuación, dónde colocarlo y qué aspecto debe tener. El modelo usa mecanismos de atención para enfocarse en distintas partes del texto de entrada a medida que construye la escena, de modo que cuando una descripción dice "Jenny corre hacia Mike", el sistema puede deducir que la orientación de Jenny depende de dónde esté parado Mike. El equipo probó su enfoque en tres tareas bastante diferentes —generar escenas de clip-art tipo caricatura, predecir mapas de disposición de objetos realistas y ensamblar fotografías compuestas a partir de fragmentos de imágenes recuperados— usando el mismo marco subyacente con solo modificaciones menores para cada una. En comparaciones directas, Text2Scene igualó o superó a sus rivales basados en GAN en la mayoría de las métricas automáticas de calidad y los superó a todos, incluido el sólido modelo AttnGAN, cuando evaluadores humanos juzgaron qué imágenes coincidían mejor con sus descripciones. El trabajo es notable tanto porque evita el notoriamente delicado proceso de entrenamiento de las GAN como porque produce salidas interpretables, paso a paso, que facilitan entender por qué el modelo tomó las decisiones que tomó, una cualidad de la que los sistemas de generación puramente basados en píxeles suelen carecer.
resumen
En este artículo, proponemos Text2Scene, un modelo que genera diversas formas de representaciones composicionales de escenas a partir de descripciones en lenguaje natural. A diferencia de trabajos recientes, nuestro método NO utiliza Redes Generativas Adversarias (GANs). En cambio, Text2Scene aprende a generar de manera secuencial objetos y sus atributos (ubicación, tamaño, apariencia, etc.) en cada paso temporal atendiendo a distintas partes del texto de entrada y al estado actual de la escena generada. Mostramos que, con modificaciones menores, el marco propuesto puede manejar la generación de diferentes formas de representaciones de escenas, incluyendo escenas tipo caricatura, disposiciones de objetos correspondientes a imágenes reales e imágenes sintéticas. Nuestro método no solo es competitivo en comparación con los métodos basados en GAN de vanguardia según métricas automáticas y superior según los juicios humanos, sino que además tiene la ventaja de producir resultados interpretables.
detalles
cita
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}