Text2Scene: Generating Compositional Scenes from Textual Descriptions
Résumé du communiqué de presse
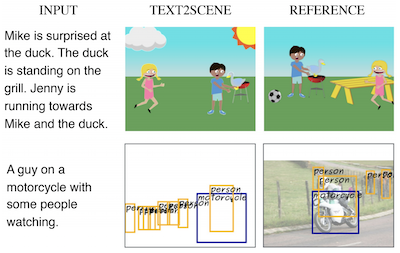
Des chercheurs de l'université de Virginie et du centre de recherche Thomas J. Watson d'IBM ont mis au point un système appelé Text2Scene qui peut générer automatiquement des scènes visuelles à partir de descriptions écrites — sans recourir aux réseaux antagonistes génératifs, ou GAN, dont dépendent la plupart des approches concurrentes. Plutôt que de tenter de synthétiser une image entière d'un seul coup, le système fonctionne davantage comme un illustrateur méticuleux, lisant une phrase puis plaçant les objets un à un sur une toile vierge, décidant à chaque étape quoi ajouter ensuite, où le placer et à quoi il devrait ressembler. Le modèle utilise des mécanismes d'attention pour se concentrer sur différentes parties du texte d'entrée à mesure qu'il construit la scène, de sorte que lorsqu'une description indique « Jenny court vers Mike », le système peut déterminer que l'orientation de Jenny dépend de l'endroit où Mike se tient déjà. L'équipe a testé son approche sur trois tâches assez différentes — générer des scènes de clip-art de type dessin animé, prédire des cartes de disposition d'objets réalistes et assembler des photographies composites à partir d'imagettes récupérées — en utilisant le même cadre sous-jacent avec seulement des modifications mineures pour chacune. Lors de comparaisons directes, Text2Scene a égalé ou dépassé ses rivaux fondés sur les GAN sur la plupart des métriques de qualité automatiques et les a tous surpassés, y compris le solide modèle AttnGAN, lorsque des évaluateurs humains ont jugé quelles images correspondaient le mieux à leurs légendes. Ces travaux sont remarquables à la fois parce qu'ils contournent le processus d'entraînement des GAN, notoirement capricieux, et parce qu'ils produisent des sorties interprétables, étape par étape, qui facilitent la compréhension des choix faits par le modèle — une qualité qui fait généralement défaut aux systèmes de génération purement fondés sur les pixels.
résumé
Dans cet article, nous proposons Text2Scene, un modèle qui génère diverses formes de représentations de scènes compositionnelles à partir de descriptions en langage naturel. Contrairement aux travaux récents, notre méthode n'utilise PAS de réseaux antagonistes génératifs (GAN). Text2Scene apprend au contraire à générer séquentiellement des objets et leurs attributs (emplacement, taille, apparence, etc.) à chaque pas de temps en portant son attention sur différentes parties du texte d'entrée et sur l'état actuel de la scène générée. Nous montrons que, moyennant des modifications mineures, le cadre proposé peut gérer la génération de différentes formes de représentations de scènes, y compris des scènes de type dessin animé, des dispositions d'objets correspondant à des images réelles et des images synthétiques. Notre méthode est non seulement compétitive par rapport aux méthodes fondées sur les GAN à l'état de l'art selon les métriques automatiques et supérieure selon les jugements humains, mais elle présente aussi l'avantage de produire des résultats interprétables.
détails
citation
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}