Text2Scene: Generating Compositional Scenes from Textual Descriptions
Tóm tắt thông cáo báo chí
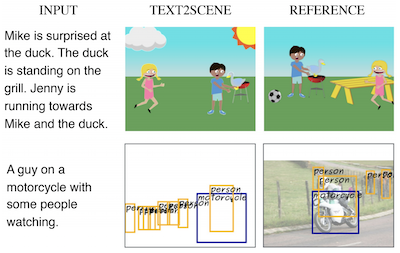
Các nhà nghiên cứu tại University of Virginia và Thomas J. Watson Research Center của IBM đã phát triển một hệ thống gọi là Text2Scene có thể tự động tạo ra các cảnh trực quan từ các mô tả bằng chữ — mà không dựa vào Generative Adversarial Networks, hay GAN, mà hầu hết các cách tiếp cận cạnh tranh phụ thuộc vào. Thay vì cố tổng hợp toàn bộ một ảnh cùng một lúc, hệ thống hoạt động giống một họa sĩ minh họa cẩn thận hơn, đọc một câu rồi đặt các đối tượng từng cái một lên một canvas trắng, quyết định ở mỗi bước sẽ thêm gì tiếp theo, đặt nó ở đâu, và nó nên trông như thế nào. Mô hình sử dụng các cơ chế chú ý để tập trung vào các phần khác nhau của văn bản đầu vào khi nó xây dựng cảnh, vì vậy khi một mô tả nói "Jenny đang chạy về phía Mike," hệ thống có thể tìm ra rằng hướng của Jenny phụ thuộc vào nơi Mike đang đứng. Nhóm đã kiểm tra cách tiếp cận của họ trên ba tác vụ khá khác nhau — tạo các cảnh clip-art hoạt hình, dự đoán các bản đồ bố cục đối tượng thực tế, và lắp ráp các bức ảnh tổng hợp từ các mảng ảnh được truy hồi — sử dụng cùng một framework nền tảng với chỉ những sửa đổi nhỏ cho mỗi tác vụ. Trong các so sánh trực tiếp, Text2Scene ngang bằng hoặc đánh bại các đối thủ dựa trên GAN trên hầu hết các thước đo chất lượng tự động và vượt trội hơn tất cả chúng, bao gồm cả mô hình AttnGAN mạnh mẽ, khi các đánh giá viên là con người phán xét ảnh nào khớp tốt hơn với chú thích của họ. Công trình này đáng chú ý vừa vì nó né tránh quy trình huấn luyện GAN nổi tiếng là khó tính, vừa vì nó tạo ra các đầu ra có thể diễn giải, từng bước một, giúp dễ hiểu hơn lý do tại sao mô hình đưa ra các lựa chọn mà nó đã đưa ra — một phẩm chất mà các hệ thống tạo sinh thuần túy dựa trên điểm ảnh nói chung thiếu.
tóm tắt
Trong bài báo này, chúng tôi đề xuất Text2Scene, một mô hình tạo ra các dạng biểu diễn cảnh tổ hợp khác nhau từ các mô tả ngôn ngữ tự nhiên. Khác với các công trình gần đây, phương pháp của chúng tôi KHÔNG sử dụng Generative Adversarial Networks (GANs). Thay vào đó, Text2Scene học cách lần lượt tạo ra các đối tượng và các thuộc tính của chúng (vị trí, kích thước, hình thức, v.v.) tại mỗi bước thời gian bằng cách chú ý đến các phần khác nhau của văn bản đầu vào và trạng thái hiện tại của cảnh được tạo ra. Chúng tôi cho thấy rằng với các sửa đổi nhỏ, framework được đề xuất có thể xử lý việc tạo ra các dạng biểu diễn cảnh khác nhau, bao gồm các cảnh giống hoạt hình, các bố cục đối tượng tương ứng với ảnh thực, và các ảnh tổng hợp. Phương pháp của chúng tôi không chỉ có tính cạnh tranh khi so sánh với các phương pháp dựa trên GAN tốt nhất hiện nay bằng các thước đo tự động và vượt trội dựa trên đánh giá của con người, mà còn có ưu điểm là tạo ra các kết quả có thể diễn giải.
chi tiết
trích dẫn
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}