Text2Scene: Generating Compositional Scenes from Textual Descriptions
Краткое изложение пресс-релиза
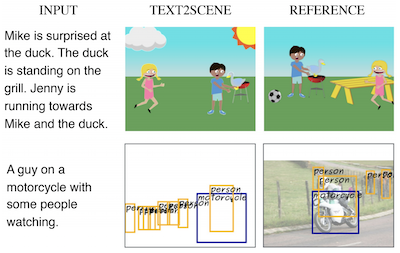
Исследователи из University of Virginia и исследовательского центра IBM Thomas J. Watson Research Center разработали систему под названием Text2Scene, которая может автоматически генерировать визуальные сцены из письменных описаний — без опоры на генеративно-состязательные сети, или GAN, на которые полагается большинство конкурирующих подходов. Вместо того чтобы пытаться синтезировать целое изображение сразу, система работает скорее как внимательный иллюстратор, читая предложение и затем размещая объекты по одному на пустом холсте, решая на каждом шаге, что добавить следующим, куда это поместить и как это должно выглядеть. Модель использует механизмы внимания, чтобы фокусироваться на различных частях входного текста по мере построения сцены, поэтому, когда описание говорит «Дженни бежит к Майку», система может выяснить, что ориентация Дженни зависит от того, где уже стоит Майк. Команда протестировала свой подход на трёх довольно разных задачах — генерация мультяшных клип-арт сцен, предсказание реалистичных карт разметки объектов и сборка составных фотографий из извлечённых фрагментов изображений — используя одну и ту же базовую структуру лишь с незначительными модификациями для каждой. В прямых сравнениях Text2Scene сравнялся с соперниками на основе GAN или превзошёл их по большинству автоматических метрик качества и превзошёл их все, включая сильную модель AttnGAN, когда люди-оценщики судили, какие изображения лучше соответствуют своим подписям. Работа примечательна как тем, что она обходит печально известный капризный процесс обучения GAN, так и тем, что она производит интерпретируемые, пошаговые выходы, которые облегчают понимание того, почему модель сделала те или иные выборы, — качество, которого обычно лишены чисто пиксельные системы генерации.
аннотация
В этой статье мы предлагаем Text2Scene — модель, которая генерирует различные формы композиционных представлений сцен из описаний на естественном языке. В отличие от недавних работ, наш метод НЕ использует генеративно-состязательные сети (Generative Adversarial Networks, GANs). Вместо этого Text2Scene учится последовательно генерировать объекты и их атрибуты (расположение, размер, внешний вид и т. д.) на каждом временном шаге, обращая внимание на различные части входного текста и текущее состояние генерируемой сцены. Мы показываем, что при незначительных модификациях предложенная структура может обрабатывать генерацию различных форм представлений сцен, включая мультяшные сцены, разметки объектов, соответствующие реальным изображениям, и синтетические изображения. Наш метод не только конкурентоспособен по сравнению с современными методами на основе GAN при использовании автоматических метрик и превосходит их по человеческим суждениям, но также имеет преимущество в виде получения интерпретируемых результатов.
подробности
цитирование
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}