AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Résumé du communiqué de presse
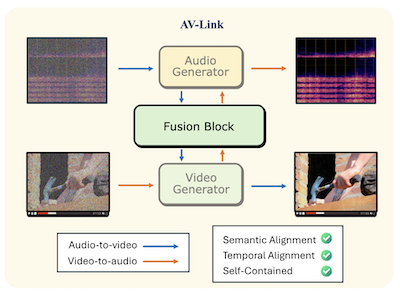
Des chercheurs de l'université Rice et de Snap Inc. ont mis au point un système appelé AV-Link capable de générer un son synchronisé à partir d'une vidéo silencieuse, ou de générer une vidéo correspondant à un clip audio donné, à l'aide d'un seul cadre unifié plutôt que des outils spécialisés distincts qui ont dominé ce domaine. Le problème central abordé par l'équipe est l'alignement temporel : faire en sorte que la sortie générée se synchronise réellement avec les événements du matériau source, de sorte que, par exemple, un coup de tambour tombe précisément au moment où la baguette frappe, plutôt que de simplement ressembler vaguement à un tambour. La plupart des approches existantes s'appuient sur des extracteurs de caractéristiques pré-entraînés comme CLIP ou ImageBind pour extraire le sens sémantique d'une modalité et le fournir à un générateur pour l'autre, mais ces extracteurs n'ont jamais été conçus en tenant compte d'un calage temporel précis. AV-Link, à la place, puise directement dans les activations internes de modèles de diffusion audio et vidéo figés et pré-entraînés, dont les chercheurs ont constaté qu'elles contiennent déjà une riche information temporelle, sous-produit de l'apprentissage de la génération de signaux variant dans le temps. Un module léger appelé Fusion Block — ajoutant environ 186 millions de paramètres au-dessus des modèles de base figés — relie les deux générateurs au moyen d'une opération d'auto-attention partagée dotée d'un plongement positionnel rotatif spécialement conçu qui aligne les tokens audio et vidéo sur le même référentiel temporel. Sur le banc d'essai standard VGGSounds, le système a amélioré l'exactitude d'attaque (onset accuracy), une mesure de la bonne correspondance entre événements sonores et événements visuels, de jusqu'à 76 % par rapport à la meilleure référence concurrente, et dans les études auprès des utilisateurs, il a été préféré au modèle MovieGen Audio de Meta, bien plus grand, pour l'alignement temporel dans 63,6 % des cas. L'intérêt pratique est qu'un seul système compact pourrait gérer la génération texte-vers-audio, texte-vers-vidéo, vidéo-vers-audio et audio-vers-vidéo, simplifiant potentiellement les pipelines de production pour des applications allant de la post-production cinématographique automatisée aux médias générés par IA.
résumé
Nous proposons AV-Link, un cadre unifié pour la génération Vidéo-vers-Audio (A2V) et Audio-vers-Vidéo (A2V) qui exploite les activations de modèles de diffusion vidéo et audio figés pour un conditionnement intermodal temporellement aligné. La clé de notre cadre est un Fusion Block qui facilite l'échange bidirectionnel d'informations entre les modèles de diffusion vidéo et audio au moyen d'opérations d'auto-attention temporellement alignées. Contrairement aux travaux antérieurs qui utilisent des modèles dédiés pour les tâches A2V et V2A et s'appuient sur des extracteurs de caractéristiques pré-entraînés, AV-Link accomplit les deux tâches dans un seul cadre autonome, exploitant directement les caractéristiques obtenues par la modalité complémentaire (c'est-à-dire les caractéristiques vidéo pour générer l'audio, ou les caractéristiques audio pour générer la vidéo). Des évaluations automatiques et subjectives approfondies démontrent que notre méthode obtient une amélioration substantielle de la synchronisation audio-vidéo, surpassant des références plus coûteuses telles que le modèle vidéo-vers-audio MovieGen.
détails
citation
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}