AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Tóm tắt thông cáo báo chí
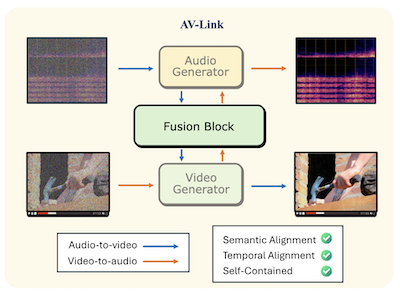
Các nhà nghiên cứu từ Rice University và Snap Inc. đã phát triển một hệ thống tên là AV-Link, có thể sinh âm thanh được đồng bộ từ video câm, hoặc sinh video để khớp với một đoạn âm thanh cho trước, bằng cách dùng một framework hợp nhất duy nhất thay vì các công cụ chuyên dụng riêng biệt vốn đã thống trị lĩnh vực này. Vấn đề cốt lõi mà nhóm giải quyết là sự căn chỉnh về thời gian — khiến đầu ra được sinh ra thực sự đồng bộ với các sự kiện trong nguồn gốc, sao cho, chẳng hạn, một tiếng trống vang lên đúng lúc dùi trống đập xuống, thay vì chỉ nghe lờ mờ giống tiếng trống. Hầu hết các cách tiếp cận hiện có dựa vào các bộ trích xuất đặc trưng đã tiền huấn luyện như CLIP hoặc ImageBind để rút ý nghĩa ngữ nghĩa từ một phương thức và đưa nó vào một bộ sinh cho phương thức kia, nhưng các bộ trích xuất này chưa bao giờ được thiết kế với sự quan tâm đến căn thời gian chặt chẽ. Thay vào đó, AV-Link kết nối trực tiếp vào các kích hoạt nội tại của các mô hình diffusion âm thanh và video đã được đóng băng, tiền huấn luyện, mà các nhà nghiên cứu nhận thấy vốn đã chứa thông tin thời gian phong phú như một sản phẩm phụ của việc học sinh ra các tín hiệu biến thiên theo thời gian. Một mô-đun nhẹ tên là Fusion Block — bổ sung khoảng 186 triệu tham số lên trên các mô hình nền đã đóng băng — kết nối hai bộ sinh thông qua một phép self-attention chung với một rotary position embedding được thiết kế đặc biệt nhằm căn chỉnh các token âm thanh và video về cùng một khung tham chiếu thời gian. Trên benchmark VGGSounds tiêu chuẩn, hệ thống cải thiện độ chính xác khởi đầu (onset accuracy), một thước đo về mức độ các sự kiện âm thanh khớp với các sự kiện thị giác, lên tới 76 phần trăm so với baseline cạnh tranh tốt nhất, và trong các nghiên cứu người dùng, nó được ưa chuộng hơn mô hình MovieGen Audio lớn hơn nhiều của Meta về căn chỉnh thời gian trong 63,6 phần trăm số lần. Ý nghĩa thực tiễn là một hệ thống nhỏ gọn duy nhất có thể xử lý sinh văn-bản-sang-âm-thanh, văn-bản-sang-video, video-sang-âm-thanh và âm-thanh-sang-video, có khả năng đơn giản hóa các quy trình sản xuất cho các ứng dụng từ hậu kỳ phim tự động đến truyền thông được tạo bởi AI.
tóm tắt
Chúng tôi đề xuất AV-Link, một framework hợp nhất cho việc sinh Video-sang-Âm thanh (V2A) và Âm thanh-sang-Video (A2V), tận dụng các kích hoạt của các mô hình diffusion video và âm thanh đã đóng băng để điều kiện hóa liên-phương-thức được căn chỉnh về mặt thời gian. Chìa khóa cho framework của chúng tôi là một Fusion Block (Khối Hợp nhất) tạo điều kiện cho việc trao đổi thông tin hai chiều giữa các mô hình diffusion video và âm thanh thông qua các phép self attention được căn chỉnh về mặt thời gian. Không giống các công trình trước đây sử dụng các mô hình chuyên dụng cho các tác vụ A2V và V2A và dựa vào các bộ trích xuất đặc trưng đã tiền huấn luyện, AV-Link đạt được cả hai tác vụ trong một framework duy nhất, tự chứa, trực tiếp tận dụng các đặc trưng thu được từ phương thức bổ trợ (tức là các đặc trưng video để sinh âm thanh, hoặc các đặc trưng âm thanh để sinh video). Các đánh giá tự động và chủ quan rộng rãi chứng minh rằng phương pháp của chúng tôi đạt được một cải thiện đáng kể trong việc đồng bộ âm thanh-video, vượt trội hơn các baseline tốn kém hơn như mô hình video-sang-âm-thanh MovieGen.
chi tiết
trích dẫn
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}