AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Resumo do comunicado de imprensa
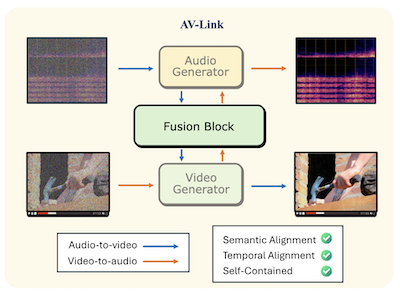
Pesquisadores da Rice University e da Snap Inc. desenvolveram um sistema chamado AV-Link que pode gerar áudio sincronizado a partir de vídeo sem som, ou gerar vídeo para corresponder a um clipe de áudio dado, usando um único framework unificado em vez das ferramentas especializadas separadas que dominaram essa área. O problema central que a equipe enfrentou é o alinhamento temporal — fazer com que a saída gerada realmente se sincronize com os eventos do material de origem, de modo que, por exemplo, uma batida de tambor ocorra exatamente quando a baqueta atinge, em vez de apenas soar vagamente como um tambor. A maioria das abordagens existentes depende de extratores de características pré-treinados como CLIP ou ImageBind para extrair o significado semântico de uma modalidade e alimentá-lo a um gerador da outra, mas esses extratores nunca foram projetados com a sincronização precisa em mente. Em vez disso, o AV-Link acessa diretamente as ativações internas de modelos de difusão de áudio e vídeo congelados e pré-treinados, que os pesquisadores descobriram já conter informação temporal rica como um subproduto do aprendizado de gerar sinais que variam no tempo. Um módulo leve chamado Fusion Block — adicionando cerca de 186 milhões de parâmetros sobre os modelos base congelados — conecta os dois geradores por meio de uma operação compartilhada de self-attention com um rotary position embedding especialmente projetado que alinha os tokens de áudio e vídeo ao mesmo referencial temporal. No benchmark padrão VGGSounds, o sistema melhorou a acurácia de onset, uma medida de quão bem os eventos sonoros se alinham aos eventos visuais, em até 76 por cento em relação à melhor baseline concorrente, e em estudos com usuários foi preferido ao modelo MovieGen Audio da Meta, muito maior, quanto ao alinhamento temporal em 63,6 por cento das vezes. A relevância prática é que um único sistema compacto poderia lidar com geração de texto para áudio, texto para vídeo, vídeo para áudio e áudio para vídeo, potencialmente simplificando os pipelines de produção para aplicações que vão da pós-produção cinematográfica automatizada à mídia gerada por IA.
resumo
Propomos o AV-Link, um framework unificado para geração de Vídeo-para-Áudio (A2V) e de Áudio-para-Vídeo (A2V) que aproveita as ativações de modelos de difusão de vídeo e áudio congelados para um condicionamento cross-modal temporalmente alinhado. A chave do nosso framework é um Fusion Block que facilita a troca bidirecional de informações entre os modelos de difusão de vídeo e áudio por meio de operações de self attention temporalmente alinhadas. Diferentemente de trabalhos anteriores que usam modelos dedicados para as tarefas de A2V e V2A e dependem de extratores de características pré-treinados, o AV-Link realiza ambas as tarefas em um único framework autocontido, aproveitando diretamente as características obtidas pela modalidade complementar (isto é, características de vídeo para gerar áudio, ou características de áudio para gerar vídeo). Avaliações automáticas e subjetivas extensas demonstram que nosso método alcança uma melhoria substancial na sincronização áudio-vídeo, superando baselines mais custosas como o modelo de vídeo para áudio do MovieGen.
detalhes
citação
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}