AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
新闻稿摘要
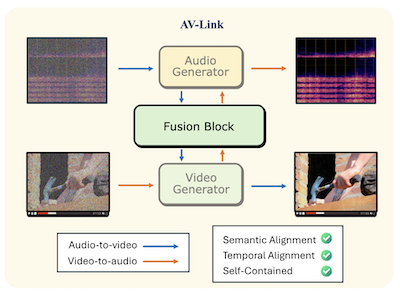
莱斯大学和 Snap Inc. 的研究人员开发了一个名为 AV-Link 的系统,它能够从无声视频生成同步音频,或生成视频以匹配给定的音频片段,使用的是单一统一框架,而非长期主导该领域的各类专用工具。研究团队所攻克的核心问题是时间对齐——让生成的输出与源素材中的事件真正同步,从而使得诸如鼓点恰好在鼓槌击打时落下,而不仅仅是听起来隐约像鼓声。大多数现有方法依赖 CLIP 或 ImageBind 等预训练特征提取器,从一种模态中提取语义并将其馈送给另一种模态的生成器,但这些提取器从未针对精确的时间控制而设计。相反,AV-Link 直接接入冻结的、预训练的音频和视频扩散模型的内部激活值,研究人员发现,作为学习生成时变信号的副产品,这些激活值已经蕴含了丰富的时间信息。一个名为 Fusion Block 的轻量级模块——在冻结的基础模型之上增加约 1.86 亿个参数——通过一个共享的自注意力操作连接两个生成器,并采用专门设计的旋转位置编码,将音频和视频 token 对齐到相同的时间参考框架。在标准的 VGGSounds 基准上,该系统将起始点准确度(衡量声音事件与视觉事件对齐程度的指标)相比最优竞争基线提升了最多 76%,并且在用户研究中,在时间对齐方面有 63.6% 的情况下被认为优于 Meta 规模大得多的 MovieGen Audio 模型。其实际意义在于,单一紧凑的系统就能处理文本到音频、文本到视频、视频到音频以及音频到视频的生成,有望简化从自动化影视后期制作到 AI 生成媒体等各类应用的制作流程。
摘要
我们提出 AV-Link,一个用于视频到音频(V2A)和音频到视频(A2V)生成的统一框架,它利用冻结的视频和音频扩散模型的激活值,实现时间对齐的跨模态条件控制。我们框架的关键是一个 Fusion Block,它通过时间对齐的自注意力操作,促进视频与音频扩散模型之间的双向信息交换。与先前为 A2V 和 V2A 任务使用专用模型并依赖预训练特征提取器的工作不同,AV-Link 在单一自包含框架中完成这两项任务,直接利用从互补模态获得的特征(即用视频特征生成音频,或用音频特征生成视频)。大量的自动评估和主观评估表明,我们的方法在音视频同步方面取得了显著改进,超越了诸如 MovieGen 视频到音频模型等成本更高的基线。
详情
引用
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}