ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Résumé du communiqué de presse
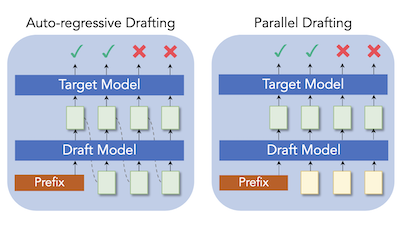
Des chercheurs de Rice University et du Tencent AI Lab ont mis au point une nouvelle technique appelée ParallelSpec qui accélère une méthode populaire visant à rendre plus rapide l'inférence des grands modèles de langage. Le défi sous-jacent est que les systèmes dits de décodage spéculatif — qui utilisent un petit modèle « rédacteur » pour proposer rapidement un texte candidat qu'un modèle cible plus grand vérifie ensuite en parallèle — obligent encore ce petit rédacteur à générer les jetons un à la fois, créant un goulot d'étranglement d'autant plus long que l'on demande au rédacteur de prédire davantage de jetons. Pour résoudre ce problème, l'équipe a construit un seul modèle de rédaction léger qui prédit plusieurs jetons futurs simultanément en une seule passe avant, en utilisant des jetons de remplacement « masque » spécialement entraînés pour inciter le modèle à anticiper sans fonctionner de manière séquentielle. Ils ont également conçu une procédure d'entraînement soignée, appelée entraînement parallèle par groupes, pour éviter les écarts entre la manière dont le modèle est entraîné et celle dont il fonctionne réellement au moment de l'inférence. Une fois intégrée à deux cadres de décodage spéculatif établis, Medusa et EAGLE, l'approche a apporté des gains de vitesse constants sur une gamme de tâches de génération de texte, dont la traduction, le résumé, le raisonnement mathématique et la réponse à des questions ; sur Llama-2-13B, elle a atteint 2,84 fois la vitesse de la génération auto-régressive standard et a augmenté d'environ 63 pour cent l'accélération de Medusa sur Vicuna-7B. Ce travail est important car il s'attaque à une inefficacité fondamentale de l'étape de rédaction plutôt que de simplement ajuster le nombre de jetons proposés, rendant potentiellement l'accélération sans perte des LLM plus pratique pour les applications en temps réel.
résumé
Le décodage spéculatif s'est révélé une solution efficace pour l'inférence des grands modèles de langage (LLM), où le petit rédacteur prédit les jetons futurs à faible coût, et le modèle cible est mis à profit pour les vérifier en parallèle. Cependant, la plupart des travaux existants rédigent encore les jetons de manière auto-régressive afin de maintenir la dépendance séquentielle dans la modélisation du langage, ce que nous considérons comme un énorme fardeau computationnel dans le décodage spéculatif. Nous présentons ParallelSpec, une alternative aux stratégies de rédaction auto-régressives des approches de décodage spéculatif de pointe. Contrairement à la rédaction auto-régressive de l'étape spéculative, nous entraînons un rédacteur parallèle pour servir de modèle spéculatif efficace. ParallelSpec apprend à prédire efficacement plusieurs jetons futurs en parallèle à l'aide d'un seul modèle, et il peut être intégré dans tout cadre de décodage spéculatif nécessitant d'aligner les distributions de sortie du rédacteur et du modèle cible avec un coût d'entraînement minimal. Les résultats expérimentaux montrent que ParallelSpec accélère les méthodes de référence en latence jusqu'à 62 % sur des bancs d'essai de génération de texte issus de différents domaines, et qu'il atteint une accélération globale de 2,84 fois sur le modèle Llama-2-13B selon des critères d'évaluation tiers.
détails
citation
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}