新闻稿摘要
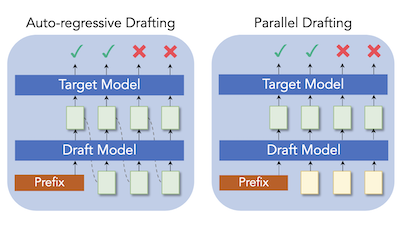
莱斯大学和腾讯 AI Lab 的研究人员开发了一种名为 ParallelSpec 的新技术,能够加速一种用于提升大语言模型推理速度的流行方法。其根本挑战在于:所谓的投机解码系统——它使用一个小型“起草”模型快速提出候选文本,再由更大的目标模型并行进行检查——仍然迫使这个小型起草模型逐个生成 token,从而形成一个瓶颈,而且被要求预测的 token 越多,这个瓶颈就越严重。为解决这一问题,研究团队构建了一个单一的轻量级起草模型,能在一次前向传播中同时预测多个未来 token,并使用经过专门训练的占位“掩码”token 来提示模型向前展望,而无需顺序运行。他们还设计了一套精心安排的训练流程,称为分组并行训练(group-wise parallel training),以防止模型的训练方式与其在推理时实际运行方式之间出现不匹配。当该方法接入两个成熟的投机解码框架 Medusa 和 EAGLE 时,它在包括翻译、摘要、数学推理和问答在内的一系列文本生成任务中带来了一致的速度提升;在 Llama-2-13B 上,它达到了标准自回归生成速度的 2.84 倍,并将 Medusa 在 Vicuna-7B 上的加速比提升了约 63%。这项工作之所以重要,是因为它解决了起草阶段中一个根本性的低效问题,而不仅仅是调整提出多少 token,有望让无损的 LLM 加速对实时应用更加实用。
摘要
投机解码(Speculative decoding)已被证明是大语言模型(LLM)推理的一种高效解决方案,其中小型起草模型(drafter)以较低成本预测未来的 token,再利用目标模型并行地对其进行验证。然而,大多数现有工作仍以自回归方式起草 token,以保持语言建模中的顺序依赖关系,我们认为这在投机解码中构成了巨大的计算负担。我们提出了 ParallelSpec,作为最先进投机解码方法中自回归起草策略的一种替代方案。与投机阶段的自回归起草不同,我们训练一个并行起草模型,使其充当高效的投机模型。ParallelSpec 学会使用单一模型高效地并行预测多个未来 token,并且能够以极小的训练成本集成到任何需要对齐起草模型与目标模型输出分布的投机解码框架中。实验结果表明,在来自不同领域的文本生成基准上,ParallelSpec 将基线方法的延迟最高加速了 62%,并且在使用第三方评估标准的 Llama-2-13B 模型上实现了 2.84 倍的整体加速。
详情
引用
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}