ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Sintesi del comunicato stampa
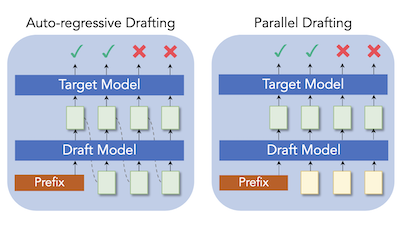
I ricercatori della Rice University e del Tencent AI Lab hanno sviluppato una nuova tecnica chiamata ParallelSpec che velocizza un metodo molto utilizzato per rendere più rapida l'inferenza dei large language model. La sfida di fondo è che i cosiddetti sistemi di decoding speculativo — che usano un piccolo modello "draft" per proporre rapidamente testo candidato che un modello target più grande verifica poi in parallelo — costringono ancora quel piccolo drafter a generare i token uno alla volta, creando un collo di bottiglia che si allunga quanto più numerosi sono i token che al drafter viene chiesto di predire. Per risolvere questo problema, il team ha costruito un singolo e leggero modello draft che predice più token futuri simultaneamente in un unico passaggio in avanti, utilizzando token segnaposto "mask" appositamente addestrati per indurre il modello a guardare avanti senza procedere in sequenza. Hanno inoltre progettato un'accurata procedura di addestramento, chiamata group-wise parallel training, per prevenire disallineamenti tra come il modello viene addestrato e come effettivamente opera in fase di inferenza. Inserito in due affermati framework di decoding speculativo, Medusa ed EAGLE, l'approccio ha fornito guadagni di velocità costanti su una serie di compiti di generazione di testo, tra cui traduzione, riassunto, ragionamento matematico e domanda-risposta; su Llama-2-13B ha raggiunto una velocità pari a 2,84 volte quella della generazione auto-regressiva standard, e ha aumentato lo speedup di Medusa su Vicuna-7B di circa il 63 percento. Il lavoro è importante perché affronta un'inefficienza fondamentale nella fase di drafting anziché limitarsi a regolare quanti token vengono proposti, rendendo potenzialmente più pratica un'accelerazione senza perdita degli LLM per le applicazioni in tempo reale.
abstract
Il decoding speculativo si è dimostrato una soluzione efficiente per l'inferenza dei large language model (LLM), in cui il piccolo drafter predice i token futuri a basso costo, e il modello target viene sfruttato per verificarli in parallelo. Tuttavia, la maggior parte dei lavori esistenti continua a generare i token in modo auto-regressivo per mantenere la dipendenza sequenziale nel modeling del linguaggio, cosa che consideriamo un enorme onere computazionale nel decoding speculativo. Presentiamo ParallelSpec, un'alternativa alle strategie di drafting auto-regressivo negli approcci di decoding speculativo allo stato dell'arte. A differenza del drafting auto-regressivo nella fase speculativa, addestriamo un drafter parallelo che funge da modello speculativo efficiente. ParallelSpec impara a predire in modo efficiente più token futuri in parallelo utilizzando un singolo modello, e può essere integrato in qualsiasi framework di decoding speculativo che richieda l'allineamento delle distribuzioni di output del drafter e del modello target con un costo di addestramento minimo. I risultati sperimentali mostrano che ParallelSpec accelera i metodi di base in latenza fino al 62% su benchmark di generazione di testo provenienti da domini diversi, e raggiunge un overall speedup di 2,84X sul modello Llama-2-13B utilizzando criteri di valutazione di terze parti.
dettagli
citazione
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}