ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Краткое изложение пресс-релиза
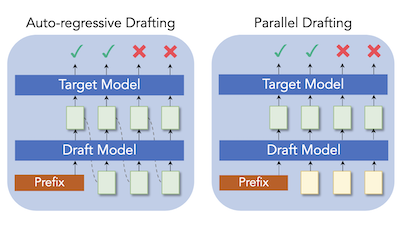
Исследователи из Rice University и Tencent AI Lab разработали новую технику под названием ParallelSpec, которая ускоряет популярный метод повышения скорости инференса больших языковых моделей. Основная проблема в том, что системы так называемого speculative decoding — использующие небольшую "черновую" модель для быстрого предложения кандидатов текста, которые более крупная целевая модель затем проверяет параллельно, — всё равно вынуждают эту небольшую черновую модель генерировать токены по одному, создавая узкое место, которое тем больше, чем больше токенов требуется предсказать. Чтобы решить эту проблему, команда построила единую легковесную черновую модель, которая предсказывает сразу несколько будущих токенов за один проход вперёд, используя специально обученные токены-заполнители "mask", побуждающие модель заглядывать вперёд без последовательной работы. Они также разработали тщательную процедуру обучения, названную group-wise parallel training, чтобы предотвратить несоответствия между тем, как модель обучается, и тем, как она реально работает на этапе инференса. При встраивании в два устоявшихся фреймворка speculative decoding, Medusa и EAGLE, подход обеспечил стабильный прирост скорости на широком наборе задач генерации текста, включая перевод, реферирование, математические рассуждения и ответы на вопросы; на Llama-2-13B он достиг скорости в 2,84 раза выше стандартной авторегрессионной генерации, а ускорение Medusa на Vicuna-7B вырос примерно на 63 процента. Работа важна тем, что устраняет фундаментальную неэффективность на этапе черновой генерации, а не просто настраивает количество предлагаемых токенов, потенциально делая ускорение LLM без потерь более практичным для приложений реального времени.
аннотация
Speculative decoding зарекомендовал себя как эффективное решение для инференса больших языковых моделей (LLM): небольшая черновая модель (drafter) с малыми затратами предсказывает будущие токены, а целевая модель используется для их параллельной проверки. Однако в большинстве существующих работ токены по-прежнему генерируются авторегрессионно, чтобы сохранить последовательную зависимость в языковом моделировании, что мы считаем огромной вычислительной нагрузкой при speculative decoding. Мы представляем ParallelSpec — альтернативу авторегрессионным стратегиям черновой генерации в современных подходах к speculative decoding. В отличие от авторегрессионной черновой генерации на спекулятивном этапе, мы обучаем параллельный drafter, выступающий в роли эффективной спекулятивной модели. ParallelSpec учится эффективно предсказывать сразу несколько будущих токенов параллельно с помощью одной модели и может быть интегрирован в любой фреймворк speculative decoding, требующий согласования выходных распределений drafter и целевой модели, при минимальных затратах на обучение. Результаты экспериментов показывают, что ParallelSpec ускоряет базовые методы по задержке (latency) до 62% на бенчмарках генерации текста из разных предметных областей и достигает общего ускорения в 2,84 раза на модели Llama-2-13B по сторонним критериям оценки.
подробности
цитирование
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}