AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation
Zusammenfassung der Pressemitteilung
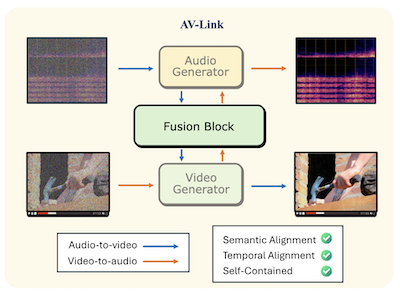
Forschende der Rice University und von Snap Inc. haben ein System namens AV-Link entwickelt, das synchronisiertes Audio aus stummem Video generieren oder Video passend zu einem gegebenen Audioclip erzeugen kann, und zwar mit einem einzigen einheitlichen Framework statt der separaten spezialisierten Werkzeuge, die dieses Feld dominiert haben. Das Kernproblem, dem sich das Team annahm, ist die zeitliche Ausrichtung — die generierte Ausgabe tatsächlich mit Ereignissen im Quellmaterial zu synchronisieren, sodass beispielsweise ein Trommelschlag genau dann erfolgt, wenn ein Trommelstock auftrifft, statt nur vage nach Trommel zu klingen. Die meisten bestehenden Ansätze stützen sich auf vortrainierte Merkmalsextraktoren wie CLIP oder ImageBind, um semantische Bedeutung aus einer Modalität zu ziehen und sie einem Generator für die andere zuzuführen, aber diese Extraktoren wurden nie mit Blick auf präzises Timing konzipiert. Stattdessen greift AV-Link direkt auf die internen Aktivierungen eingefrorener, vortrainierter Audio- und Video-Diffusionsmodelle zu, von denen die Forschenden feststellten, dass sie als Nebenprodukt des Lernens, zeitlich veränderliche Signale zu generieren, bereits reichhaltige zeitliche Informationen enthalten. Ein leichtgewichtiges Modul namens Fusion Block — das etwa 186 Millionen Parameter zu den eingefrorenen Basismodellen hinzufügt — verbindet die beiden Generatoren über eine gemeinsame Self-Attention-Operation mit einem speziell entworfenen rotatorischen Positions-Embedding, das Audio- und Video-Token am selben zeitlichen Referenzrahmen ausrichtet. Auf dem standardmäßigen VGGSounds-Benchmark verbesserte das System die Onset-Genauigkeit, ein Maß dafür, wie gut Klangereignisse mit visuellen Ereignissen übereinstimmen, um bis zu 76 Prozent gegenüber der besten konkurrierenden Baseline, und in Nutzerstudien wurde es in 63,6 Prozent der Fälle gegenüber Metas viel größerem MovieGen-Audio-Modell für die zeitliche Ausrichtung bevorzugt. Die praktische Bedeutung besteht darin, dass ein einziges kompaktes System Text-zu-Audio-, Text-zu-Video-, Video-zu-Audio- und Audio-zu-Video-Generierung bewältigen könnte, was Produktions-Pipelines für Anwendungen von der automatisierten Filmnachbearbeitung bis hin zu KI-generierten Medien potenziell vereinfacht.
Zusammenfassung
Wir schlagen AV-Link vor, ein einheitliches Framework für die Video-zu-Audio- (A2V) und Audio-zu-Video- (A2V) Generierung, das die Aktivierungen eingefrorener Video- und Audio-Diffusionsmodelle für eine zeitlich ausgerichtete crossmodale Konditionierung nutzt. Der Schlüssel zu unserem Framework ist ein Fusion Block, der einen bidirektionalen Informationsaustausch zwischen Video- und Audio-Diffusionsmodellen durch zeitlich ausgerichtete Self-Attention-Operationen ermöglicht. Anders als frühere Arbeiten, die dedizierte Modelle für A2V- und V2A-Aufgaben verwenden und sich auf vortrainierte Merkmalsextraktoren stützen, bewältigt AV-Link beide Aufgaben in einem einzigen, in sich geschlossenen Framework und nutzt dabei direkt die von der komplementären Modalität gewonnenen Merkmale (d. h. Videomerkmale, um Audio zu generieren, oder Audiomerkmale, um Video zu generieren). Umfangreiche automatische und subjektive Bewertungen zeigen, dass unsere Methode eine erhebliche Verbesserung der Audio-Video-Synchronisation erzielt und teurere Baselines wie das MovieGen-Video-zu-Audio-Modell übertrifft.
Details
Zitation
@inproceedings{hajiali2025av,
title = {AV-Link: Temporally-Aligned Diffusion Features for Cross-Modal Audio-Video Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Canberk, Alper and Lee, Kwot Sin and Ordonez, Vicente and Tulyakov, Sergey},
year = {2025},
booktitle = {International Conference on Computer Vision. ICCV 2025},
url = {https://arxiv.org/abs/2412.15191},
}