Improved Visual Grounding through Self-Consistent Explanations
Zusammenfassung der Pressemitteilung
Forschende an der Rice University und der UC Irvine haben eine Technik entwickelt, die KI-Systemen hilft, die Position von Objekten in Bildern zuverlässiger zu bestimmen, wenn ihnen eine Textbeschreibung gegeben wird — eine Aufgabe, die als visuelles Grounding bekannt ist. Das Kernproblem, dem sie sich annahmen, besteht darin, dass bestehende Vision-Language-Modelle, die lernen, Bilder mit Text abzugleichen, ein Objekt wie ein "Frisbee" korrekt lokalisieren können, aber versagen, wenn dasselbe Objekt mit einem anderen Wort wie "Scheibe" beschrieben wird. Um dies zu beheben, schuf das Team einen Trainingsansatz namens SelfEQ (Self-consistency EQuivalence Tuning), der ein Large Language Model verwendet, um automatisch Paraphrasen für Bildunterschriften zu generieren, und dann das visuelle Modell so feinabstimmt, dass sowohl die ursprüngliche Phrase als auch ihre Paraphrase dieselbe hervorgehobene Region im Bild erzeugen. Die Methode funktioniert, ohne irgendwelche Begrenzungsrahmen-Annotationen zu erfordern, und stützt sich stattdessen auf gradientenbasierte visuelle Erklärungskarten — konkret GradCAM — als eine Form schwacher Supervision. Getestet auf drei Standard-Benchmarks, verbesserte SelfEQ die Lokalisierungsgenauigkeit um 4,69 Prozentpunkte auf Flickr30k, 7,68 Punkte auf ReferIt und durchschnittlich 3,74 Punkte auf RefCOCO+, womit es die meisten anderen Methoden übertraf, die ebenfalls auf Begrenzungsrahmen-Supervision verzichten, und sogar mit einigen mithalten konnte, die sie verwenden. Das praktische Fazit ist ein Modell, das ein breiteres Vokabular handhabt und Objekte konsistenter lokalisiert — ein nützlicher Fortschritt für Anwendungen wie visuelle Suche und Mensch-Maschine-Interaktion, die darauf angewiesen sind, Sprache mit bestimmten Teilen eines Bildes zu verbinden.
Zusammenfassung
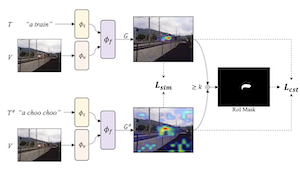
Vision-and-Language-Modelle, die darauf trainiert sind, Bilder mit Text abzugleichen, können mit visuellen Erklärungsmethoden kombiniert werden, um auf die Positionen bestimmter Objekte in einem Bild zu verweisen. Unsere Arbeit zeigt, dass die Lokalisierungs- — "Grounding"- — Fähigkeiten dieser Modelle durch Feinabstimmen auf selbstkonsistente visuelle Erklärungen weiter verbessert werden können. Wir schlagen eine Strategie vor, um bestehende Text-Bild-Datensätze mithilfe eines Large Language Model um Paraphrasen zu erweitern, sowie SelfEQ, eine schwach überwachte Strategie auf visuellen Erklärungskarten für Paraphrasen, die Selbstkonsistenz fördert. Konkret versuchen wir für eine textuelle Eingabephrase, eine Paraphrase zu generieren, und stimmen das Modell so fein ab, dass die Phrase und die Paraphrase auf dieselbe Region im Bild abbilden. Wir postulieren, dass dies sowohl das Vokabular erweitert, das das Modell handhaben kann, als auch die Qualität der durch gradientenbasierte visuelle Erklärungsmethoden (z. B. GradCAM) hervorgehobenen Objektpositionen verbessert. Wir zeigen, dass SelfEQ die Leistung auf Flickr30k, ReferIt und RefCOCO+ gegenüber einer starken Baseline-Methode und mehreren früheren Arbeiten verbessert. Insbesondere erreichen wir im Vergleich zu anderen Methoden, die keinerlei Box-Annotationen verwenden, 84,07 % auf Flickr30k (eine absolute Verbesserung von 4,69 %), 67,40 % auf ReferIt (eine absolute Verbesserung von 7,68 %) sowie 75,10 % bzw. 55,49 % auf den RefCOCO+-Testmengen A und B (eine absolute Verbesserung von durchschnittlich 3,74 %).
Details
Zitation
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Welches Problem adressiert SelfEQ? SelfEQ verbessert das visuelle Grounding, indem es ein Vision-Language-Modell dazu bringt, äquivalente Phrasen wie "Frisbee" und "Scheibe" in derselben Bildregion zu lokalisieren.
- Wie funktioniert die Methode ohne Begrenzungsrahmen-Supervision? Sie verwendet GradCAM-Erklärungskarten aus einem bestehenden Vision-Language-Modell als schwache Supervision und trainiert dann das Modell so, dass eine ursprüngliche Phrase und ihre Paraphrase konsistente Lokalisierungskarten erzeugen.
- Warum sind LLM-generierte Paraphrasen hier nützlich? Die Paraphrasen erweitern die Formulierungen, die das Modell handhaben kann, und schaffen Äquivalenzpaare, die das Modell lehren, semantisch ähnliche Beschreibungen konsistent zu verankern.
- Welche Rolle spielt das SelfEQ-Ziel? Das Ziel kombiniert Heatmap-Ähnlichkeit mit einem Konsistenzterm für die Region of Interest, sodass paraphrasierte Prompts räumlich ausgerichtet werden und zugleich triviale gleichförmige Erklärungskarten vermieden werden.
- Welche Benchmarks zeigen die Wirkung der Methode? Die Arbeit berichtet über Verbesserungen auf Flickr30k, ReferIt und RefCOCO+, einschließlich starker Ergebnisse unter den Methoden, die keine Box-Annotationen verwenden.
Wichtigste Beiträge
- Die Arbeit führt Self-consistency EQuivalence Tuning ein, ein schwach überwachtes Ziel zur Verbesserung des visuellen Grounding durch konsistente Erklärungen über paraphrasierten Text hinweg.
- Sie zeigt, dass LLM-generierte Paraphrasen als skalierbare Trainingssignale für das visuelle Grounding verwendet werden können und so sprachliche Äquivalenz in nützliche räumliche Supervision verwandeln.
- Die Methode verbessert eine ALBEF-basierte Grounding-Pipeline, ohne Begrenzungsrahmen, Segmentierungsmasken, Objektdetektoren oder Box-Proposal-Netzwerke zu erfordern.
- SelfEQ erzielt erhebliche Gewinne gegenüber starken schwach überwachten Baselines, einschließlich 84,07 % auf Flickr30k, 67,40 % auf ReferIt und einer verbesserten Pointing-Game-Genauigkeit auf RefCOCO+.
- Die Ablationen verdeutlichen, warum explizites Equivalence Tuning wichtig ist: Das bloße Hinzufügen von Paraphrasen als zusätzliche Bild-Text-Paare ist weniger effektiv, als selbstkonsistente visuelle Erklärungen direkt zu erzwingen.
Grenzen und Vorbehalte
- SelfEQ ist für schwach überwachtes Grounding mit Erklärungskarten konzipiert und ergänzt daher vollständig überwachte Grounding-Systeme, statt sie zu ersetzen, wenn hochwertige Boxen verfügbar sind.
- Die Methode hängt von der Qualität der generierten Paraphrasen ab, aber die Arbeit verwendet eine klare Strategie für Prompting und Filterung und zeigt, dass die resultierenden Äquivalenzpaare praktische Gewinne liefern.
- Da sie auf GradCAM-artigen Erklärungen aus einem Basis-Vision-Language-Modell aufbaut, kann die Leistung die Stärken des zugrunde liegenden Modells widerspiegeln; dies macht SelfEQ besonders wertvoll als Feinabstimmungsstrategie zur Verbesserung bestehender Modelle.
- Die Bewertung konzentriert sich auf standardmäßige Grounding-Benchmarks und die Pointing-Game-Genauigkeit und lässt breitere reale Szenarien für visuelle Suche, Robotik und Barrierefreiheit als natürliche nächste Anwendungen offen.
- Der Ansatz konzentriert sich auf Phrasen- und Regionen-Grounding statt auf vollständiges offenes visuelles Schlussfolgern, was den Beitrag gut fokussiert hält und die berichteten Gewinne leichter interpretierbar macht.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker Beitrag zum schwach überwachten visuellen Grounding lesen: SelfEQ verwandelt Paraphrasen-Konsistenz in ein praktisches Trainingssignal und verbessert die Lokalisierungsgenauigkeit und die Vokabular-Robustheit, ohne teure Annotationen von Objektpositionen zu benötigen.