Estimating and Maximizing Mutual Information for Knowledge Distillation
Zusammenfassung der Pressemitteilung
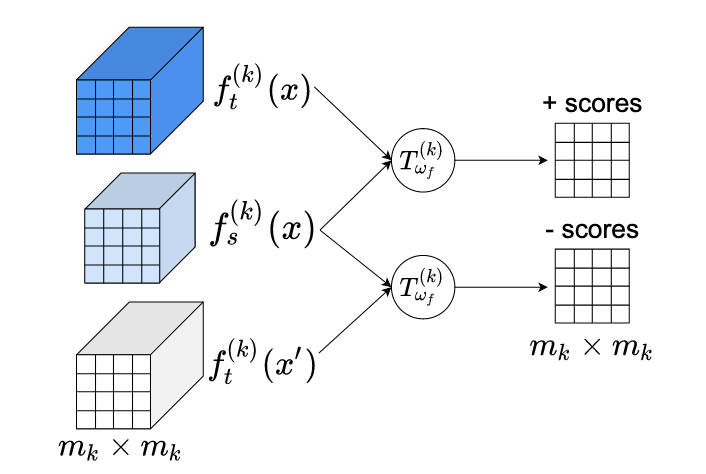
Forschende der University of Virginia und der Rice University haben eine neue Technik entwickelt, um große Modelle der künstlichen Intelligenz auf eine Größe zu verkleinern, die auf Telefonen und anderen ressourcenbeschränkten Geräten laufen kann, ohne dabei zu viel Genauigkeit einzubüßen. Die zentrale Herausforderung in diesem Feld, das als Wissensdestillation (Knowledge Distillation) bekannt ist, besteht darin, ein kleineres "Schüler"-Neuronennetz dazu zu bringen, nützliche Informationen von einem größeren, leistungsfähigeren "Lehrer"-Netz aufzunehmen. Bestehende Methoden tun dies typischerweise, indem sie die Ausgaben oder Zwischenrepräsentationen der beiden Netzwerke mithilfe einfacher Distanzmaße abgleichen, was schwierig werden kann, wenn Lehrer und Schüler sehr unterschiedliche interne Architekturen besitzen. Das neue Rahmenwerk namens MIMKD (Mutual Information Maximization Knowledge Distillation) verfolgt einen anderen Ansatz, indem es ein kontrastives Lernziel verwendet, das in der Informationstheorie verwurzelt ist – konkret einen auf der Jensen-Shannon-Divergenz beruhenden Schätzer –, um gleichzeitig die zwischen den Repräsentationen der beiden Netzwerke geteilte wechselseitige Information zu schätzen und zu maximieren, und zwar sowohl auf der Ebene der finalen globalen Merkmale als auch auf feinkörnigeren lokalen und intermediären Merkmalsebenen. Ein praktischer Vorteil ist, dass diese Formulierung – anders als konkurrierende Methoden wie Contrastive Representation Distillation – während des Trainings nur eine einzige negative Stichprobe statt Tausender benötigt, was sie weitaus speichersparsamer und besser auf intermediäre Netzwerkschichten anwendbar macht. In Tests auf den Bildklassifikations-Benchmarks CIFAR-100 und ImageNet übertraf MIMKD durchweg etablierte Alternativen über ein breites Spektrum von Lehrer-Schüler-Paarungen hinweg, einschließlich Fällen, in denen die beiden Netzwerke sehr unterschiedliche Designs hatten, und steigerte die Genauigkeit eines ShuffleNetV2 mithilfe eines ResNet-50-Lehrers um fast 5 Prozentpunkte sowie die eines ResNet-18 auf ImageNet um 1,44 Prozentpunkte gegenüber seiner Baseline – Ergebnisse, die nahelegen, dass der Ansatz dazu beitragen könnte, leistungsfähige KI-Modelle praktischer am Rand des Netzwerks (Edge) einsetzbar zu machen.
Zusammenfassung
In dieser Arbeit schlagen wir Mutual Information Maximization Knowledge Distillation (MIMKD) vor. Unsere Methode verwendet ein kontrastives Ziel, um gleichzeitig eine untere Schranke der wechselseitigen Information lokaler und globaler Merkmalsrepräsentationen zwischen einem Lehrer- und einem Schülernetzwerk zu schätzen und zu maximieren. Wir zeigen durch umfangreiche Experimente, dass dies genutzt werden kann, um die Leistung von Modellen mit geringer Kapazität zu verbessern, indem Wissen von leistungsfähigeren, aber rechenintensiveren Modellen übertragen wird. Dies kann dazu verwendet werden, bessere Modelle zu erzeugen, die auf Geräten mit geringen Rechenressourcen ausgeführt werden können. Unsere Methode ist flexibel; wir können Wissen von Lehrern mit beliebigen Netzwerkarchitekturen auf beliebige Schülernetzwerke destillieren. Unsere empirischen Ergebnisse zeigen, dass MIMKD konkurrierende Ansätze über ein breites Spektrum von Schüler-Lehrer-Paaren mit unterschiedlichen Kapazitäten, unterschiedlichen Architekturen und bei Schülernetzwerken mit extrem geringer Kapazität übertrifft. Wir erreichen mit einem ShufflenetV2 eine Genauigkeit von 74,55 % auf CIFAR100 gegenüber einer Baseline-Genauigkeit von 69,8 %, indem wir Wissen aus einem ResNet-50 destillieren. Auf Imagenet verbessern wir ein ResNet-18-Netzwerk von 68,88 % auf 70,32 % Genauigkeit (1,44 %+) mithilfe eines ResNet-34-Lehrernetzwerks.
Zitation
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}