Text2Scene: Generating Compositional Scenes from Textual Descriptions
Zusammenfassung der Pressemitteilung
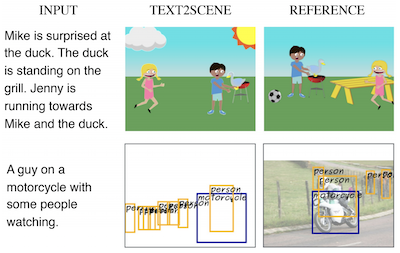
Forscher der University of Virginia und des IBM Thomas J. Watson Research Center haben ein System namens Text2Scene entwickelt, das automatisch visuelle Szenen aus schriftlichen Beschreibungen generieren kann – ohne sich auf die Generative Adversarial Networks, kurz GANs, zu stützen, von denen die meisten konkurrierenden Ansätze abhängen. Anstatt zu versuchen, ein ganzes Bild auf einmal zu synthetisieren, arbeitet das System eher wie ein sorgfältiger Illustrator, der einen Satz liest und dann Objekte nacheinander auf eine leere Leinwand setzt, wobei es bei jedem Schritt entscheidet, was als Nächstes hinzugefügt wird, wo es platziert wird und wie es aussehen soll. Das Modell nutzt Aufmerksamkeitsmechanismen, um sich beim Aufbau der Szene auf verschiedene Teile des Eingabetextes zu konzentrieren, sodass das System bei einer Beschreibung wie "Jenny is running towards Mike" erkennen kann, dass Jennys Ausrichtung davon abhängt, wo Mike bereits steht. Das Team testete seinen Ansatz an drei recht unterschiedlichen Aufgaben – der Generierung von Cartoon-Clipart-Szenen, der Vorhersage realistischer Objektanordnungskarten und dem Zusammensetzen zusammengesetzter Fotografien aus abgerufenen Bildausschnitten – und verwendete dabei dasselbe zugrunde liegende Framework mit jeweils nur geringfügigen Modifikationen. In direkten Vergleichen erreichte oder übertraf Text2Scene GAN-basierte Konkurrenten bei den meisten automatischen Qualitätsmetriken und übertraf sie alle, einschließlich des starken AttnGAN-Modells, wenn menschliche Bewerter beurteilten, welche Bilder besser zu ihren Bildunterschriften passten. Die Arbeit ist bemerkenswert, weil sie sowohl den notorisch heiklen GAN-Trainingsprozess umgeht als auch interpretierbare, schrittweise Ausgaben erzeugt, die es leichter machen zu verstehen, warum das Modell die getroffenen Entscheidungen getroffen hat – eine Eigenschaft, die rein pixelbasierten Generierungssystemen im Allgemeinen fehlt.
Zusammenfassung
In dieser Arbeit schlagen wir Text2Scene vor, ein Modell, das verschiedene Formen kompositioneller Szenenrepräsentationen aus natürlichsprachlichen Beschreibungen generiert. Anders als jüngere Arbeiten verwendet unsere Methode KEINE Generative Adversarial Networks (GANs). Stattdessen lernt Text2Scene, Objekte und ihre Attribute (Position, Größe, Erscheinungsbild usw.) zu jedem Zeitschritt sequenziell zu generieren, indem es seine Aufmerksamkeit auf verschiedene Teile des Eingabetextes und den aktuellen Stand der generierten Szene richtet. Wir zeigen, dass das vorgeschlagene Framework mit geringfügigen Modifikationen die Generierung unterschiedlicher Formen von Szenenrepräsentationen bewältigen kann, darunter cartoonartige Szenen, Objektanordnungen, die realen Bildern entsprechen, und synthetische Bilder. Unsere Methode ist nicht nur konkurrenzfähig im Vergleich zu modernsten GAN-basierten Methoden gemessen an automatischen Metriken und überlegen gemessen an menschlichen Urteilen, sondern hat zudem den Vorteil, interpretierbare Ergebnisse zu liefern.
Details
Zitation
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}