ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Zusammenfassung der Pressemitteilung
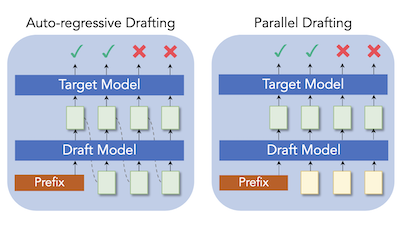
Forschende an der Rice University und dem Tencent AI Lab haben eine neue Technik namens ParallelSpec entwickelt, die eine beliebte Methode zur Beschleunigung der Inferenz von Large Language Models schneller macht. Die zugrunde liegende Herausforderung besteht darin, dass sogenannte Systeme zum spekulativen Decoding – die ein kleines „Draft“-Modell verwenden, um schnell Kandidatentext vorzuschlagen, den ein größeres Zielmodell dann parallel überprüft – diesen kleinen Drafter dennoch zwingen, Tokens einen nach dem anderen zu erzeugen, wodurch ein Engpass entsteht, der umso länger wird, je mehr Tokens der Drafter vorhersagen soll. Um dies zu beheben, baute das Team ein einzelnes leichtgewichtiges Draft-Modell, das mehrere zukünftige Tokens gleichzeitig in einem einzigen Vorwärtsdurchlauf vorhersagt, wobei speziell trainierte Platzhalter-„Mask“-Tokens verwendet werden, um das Modell dazu zu bewegen, vorauszuschauen, ohne sequentiell zu laufen. Sie entwarfen außerdem ein sorgfältiges Trainingsverfahren namens gruppenweises paralleles Training, um Diskrepanzen zwischen der Art und Weise, wie das Modell trainiert wird, und der Art und Weise, wie es zur Inferenzzeit tatsächlich läuft, zu verhindern. In zwei etablierte Frameworks für spekulatives Decoding, Medusa und EAGLE, integriert, lieferte der Ansatz konsistente Geschwindigkeitsgewinne über eine Reihe von Textgenerierungsaufgaben hinweg, darunter Übersetzung, Zusammenfassung, mathematisches Schlussfolgern und Frage-Antwort-Aufgaben; auf Llama-2-13B erreichte er das 2,84-fache der Geschwindigkeit der standardmäßigen autoregressiven Generierung und steigerte Medusas Beschleunigung auf Vicuna-7B um rund 63 Prozent. Die Arbeit ist von Bedeutung, weil sie eine grundlegende Ineffizienz in der Drafting-Phase angeht, statt lediglich anzupassen, wie viele Tokens vorgeschlagen werden, und damit eine verlustfreie LLM-Beschleunigung möglicherweise praktikabler für Echtzeitanwendungen macht.
Zusammenfassung
Spekulatives Decoding hat sich als effiziente Lösung für die Inferenz von Large Language Models (LLM) erwiesen, bei der der kleine Drafter zukünftige Tokens kostengünstig vorhersagt und das Zielmodell genutzt wird, um sie parallel zu verifizieren. Die meisten bestehenden Arbeiten entwerfen Tokens jedoch weiterhin autoregressiv, um die sequentielle Abhängigkeit in der Sprachmodellierung zu bewahren, was wir als enorme rechnerische Belastung im spekulativen Decoding betrachten. Wir präsentieren ParallelSpec, eine Alternative zu autoregressiven Drafting-Strategien in State-of-the-Art-Ansätzen des spekulativen Decodings. Im Gegensatz zum autoregressiven Drafting in der spekulativen Phase trainieren wir einen parallelen Drafter, der als effizientes spekulatives Modell dient. ParallelSpec lernt, mehrere zukünftige Tokens parallel mit einem einzigen Modell effizient vorherzusagen, und lässt sich in jedes Framework für spekulatives Decoding integrieren, das eine Ausrichtung der Ausgabeverteilungen von Drafter und Zielmodell mit minimalen Trainingskosten erfordert. Experimentelle Ergebnisse zeigen, dass ParallelSpec Baseline-Methoden in der Latenz um bis zu 62 % auf Textgenerierungs-Benchmarks aus verschiedenen Domänen beschleunigt und auf dem Llama-2-13B-Modell unter Verwendung von Drittanbieter-Bewertungskriterien eine Gesamtbeschleunigung von 2,84-fach erreicht.
Details
Zitation
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}