FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Resumen de prensa
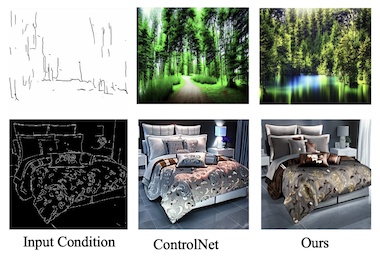
Investigadores de UC Santa Cruz, Amazon, UNC Chapel Hill, la Universidad Rice y UCLA han desarrollado una forma más eficiente de controlar generadores de imágenes con IA usando varios tipos de guía visual de forma simultánea. Los modelos de difusión de texto a imagen actuales, como Stable Diffusion, pueden orientarse mediante entradas estructurales como mapas de bordes, mapas de profundidad y mapas de segmentación, pero entrenar estos sistemas controlables suele exigir recursos computacionales sustanciales que aumentan de forma lineal a medida que se añaden más tipos de entrada. El nuevo sistema del equipo, llamado FlexEControl, aborda esto tomando prestada una técnica matemática llamada descomposición de Kronecker de la literatura más amplia de aprendizaje automático, usándola para crear un conjunto compacto de pesos compartidos que maneja distintas modalidades de entrada en lugar de aprender parámetros separados para cada una. El resultado es un modelo que usa un 41% menos de parámetros entrenables y un 30% menos de memoria que un sistema comparable de referencia llamado UniControlNet, reduciendo al mismo tiempo el tiempo de entrenamiento por iteración de unos 5.7 segundos a 2.1 segundos. Más allá de la eficiencia bruta, FlexEControl también rinde mejor al manejar múltiples entradas conflictivas o redundantes —por ejemplo, dos mapas de bordes distintos de la misma escena—, un escenario en el que los métodos existentes tienden a producir imágenes confusas o incoherentes. Los investigadores lograron esto añadiendo dos funciones de pérdida de entrenamiento especializadas que obligan al modelo a prestar atención a las regiones espaciales correctas y a alinear sus salidas con las indicaciones de texto correspondientes. En evaluaciones humanas, los anotadores prefirieron las salidas de FlexEControl el 64% de las veces frente a las de UniControlNet cuando ambos sistemas recibían múltiples entradas del mismo tipo. El trabajo es relevante porque hacer que la generación controlable de imágenes sea más económica y más capaz de manejar entradas complejas y mixtas podría ampliar significativamente el acceso a estas herramientas para desarrolladores e investigadores que trabajan con recursos de cómputo limitados.
resumen
Los modelos de difusión controlables de texto a imagen (T2I) generan imágenes condicionadas tanto por indicaciones de texto como por entradas semánticas de otras modalidades, como los mapas de bordes. No obstante, los métodos controlables actuales de T2I suelen enfrentar desafíos relacionados con la eficiencia y la fidelidad, especialmente al condicionar con múltiples entradas de la misma modalidad o de modalidades diversas. En este artículo, proponemos un método novedoso, flexible y eficiente, FlexEControl, para la generación controlable de T2I. En el núcleo de FlexEControl hay una estrategia única de descomposición de pesos que permite una integración simplificada de diversos tipos de entrada. Este enfoque no solo mejora la fidelidad de la imagen generada respecto al control, sino que también reduce significativamente la sobrecarga computacional típicamente asociada con el condicionamiento multimodal. Nuestro enfoque logra una reducción del 41% en los parámetros entrenables y del 30% en el uso de memoria en comparación con Uni-ControlNet. Además, duplica la eficiencia de datos y puede generar imágenes de manera flexible bajo la guía de múltiples condiciones de entrada de diversas modalidades.
cita
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}